文章目录[隐藏]
- 第1课 数组、Arrays工具类
- 第2课 ArrayList集合
- 第3课 toString方法、equals方法、Objects类
- 第4课 String类
- 第5课 StringBuilder类
- 第6课 Date类 、DateFormat类、SimpleDateFormat类
- 第7课 Calendar类
- 第8课 JDK8新增的日期和时间类、DateTimeFormatter类
- 第9课 System类
- 第10课 包装类
- 第11课 Runtime类、Math类、Random类
- 第12课 集合、Collection接口
- 第13课 Iterator迭代器、foreach循环、 forEach方法
- 第14课 泛型
- 第15课 List接口、LinkedList集合
- 第16课 Set接口、HashSet集合、哈希值、LinkedHashSet集合
- 第17课 TreeSet集合、Comparable接口、 Comparator接口
- 第18课 Collections工具类
- 第19课 Map接口、Entry接口 、Map集合遍历
- 第20课 HashMap集合、LinkedHashMap集合、TreeMap集合
- 第21课 Stream流
- 第22课 File类、FileFilter接口
- 第23课 IO、字节流、打印流
- 第24课 字符流
- 第25课 IO异常处理、Properties集合
- 第26课 缓冲流
- 第27课 转换流
本篇内容紧跟面向对象笔记,主要介绍Java常用类、集合、I/O等,这些内容是Java开发中最常用的基础知识。本文已完结,但随时可能对内容做出修改,欢迎各位大佬积极斧正,转载请注明出处。
Copyright © 2020-2021 AnonyEast, All rights reserved.
JavaSE笔记共有3篇文章,你可以在这里快速跳转:
第1课 数组、Arrays工具类
一、 数组的定义
方式一:
数据类型[] 数组名 = new 数据类型[长度];
定义可以存储3个整数的数组容器,代码如下:
int[] arr = new int[3];
方式二:
数据类型[] 数组名 = new 数据类型[]{元素1,元素2,元素3...};
int[] arr = new int[]{1,2,3,4,5};
方式三:
数据类型[] 数组名 = {元素1,元素2,元素3...};
int[] arr = {1,2,3,4,5};
其中,方式一和方式二,允许先创建引用,再初始化,例如:
int[] arr; arr = new int[3];
二、数组的特性
1. 数组有定长特性,长度一旦指定,不可更改。
2. 数组的长度属性: 每个数组都具有长度,而且是固定的,Java中赋予了数组的一个属性,可以获取到数组的长度,语句为: 数组名.length ,属性length的执行结果是数组的长度,int类型结果。由次可以推断出,数组的最大索引值为数组名.length-1 。
public static void main(String[] args) {
int[] arr = new int[]{1,2,3,4,5};
//打印数组长度,输出结果是5
System.out.println(arr.length);
}
3.将数组名作为返回值
当需要返回多个值时,可以返回一个数组,但用的不多。
三、JVM内存划分
Java的内存需要划分成为5个部分:
- 1.栈(Stack) :存放的都是方法中的局部变量。方法的运行一定要在栈当中运行。
局部变量:方法的参数,或者是方法{}内部的变量
作用域:一旦超出作用域,立刻从栈内存当中消失。
- 2.堆(Heap) :凡是new出来的东西,都在堆当中。
堆内存里面的东西都有一个地址值: 16进制
堆内存里面的数据,都有默认值。规则如下:
- 整数---0
- 浮点数---0.0
- 字符---'\u0000'
- 布尔值---false
- 引用类型---null
- 3.方法区(Method Area):存储.class相关信息,包含方法的信息。
- 4.本地方法栈(Native Method Stack):与操作系统相关。
- 5.寄存器(pc Register):与CPU相关
四、数组的内存图
1.有两个独立数组的内存图

2.两个引用指向同一个数组的内存图

五、Arrays工具类
Arrays是针对数组的工具类, 位于java.util包中,主要包含了操纵数组的各种静态方法,可以进行排序、查找、复制、填充等功能。大大提高了开发人员的工作效率。
1、常用方法(均为静态方法)
| type[] copyOfRange(basicType[] original, int from, int to) | 数组复制,截取下标from到下标to - 1拷贝到一个新数组中,并返回新数组 |
| String toString(Object[] original) | 将数组转换为字符串,并返回字符串 |
| void sort(basicType[] original) | 排序,默认规则为数字升序,字符串按首字母升序 |
| int binarySearch(Object[] a, T key) | 二分查找法查找指定元素,必须先排好序,返回数组a中元素key的下标,找不到返回负数 |
| void fill(Object[] a, int fromIndex, int toIndex, Object val) | 将数组a的下标从fromIndex到toIndex - 1填充为val |
import java.util.Arrays;
public class ArraysTest {
//输出数组专用方法
public static void showArray(int[] array) {
for (int i = 0; i < array.length; i++) {
System.out.print(array[i] + " ");
}
}
public static void main(String[] args) {
int[] array = new int[]{4, 16, 9, 1, 49, 81, 64, 25, 36};
//copyOfRange方法,截取下标1-4的元素拷贝到新数组
int[] arrayIntercept = Arrays.copyOfRange(array, 1, 5);
showArray(arrayIntercept);//16 9 1 49
//sort方法,排序,默认升序
Arrays.sort(array);
showArray(array);//1 4 9 16 25 36 49 64 81
//binarySearch方法,查找元素的下标,找不到返回负数。
//此方法必须先排好序才能使用
int index = Arrays.binarySearch(array, 49);
System.out.println("元素49的下标:" + index);//6
index = Arrays.binarySearch(array,999);
System.out.println("元素999的下标:" + index);//-10
//toString方法,将数组转换为字符串
String s = Arrays.toString(array);
System.out.println(s);//[1, 4, 9, 16, 25, 36, 49, 64, 81]
//fill方法,将999填充到数组的下标2-4
Arrays.fill(array,2,5,999);
showArray(array);//1 4 999 999 999 36 49 64 81
}
}
2、对象数组使用sort方法进行排序
对象数组:数组当中存储的是对象的引用,例如存放的是String类型的字符串,或者自定义的Student类的学生对象,而不是基本数据类型的int、double等。
- void sort(Object[] a):根据元素的自然顺序对对象数组中的元素按照某种规则排序,Object类型泛指任意类型的对象。使用此方法需要确保数组中的对象元素所在类中实现了Comparable接口并重写其中的compareTo方法来自定义比较规则,这样就能实现以自己定义的排序规则进行排序。
- void sort(T[] a, Comparator c):根据指定的Comparator比较器制定的比较规则对指定对象数组进行排序。使用此方法需要定义一个实现Comparator接口的类,并重写其中的compare方法来自定义比较规则,然后将该实现类对象作为参数传入此sort方法,就能实现以自己定义的排序规则进行排序。
这两种方法将在第17课学习Comparable接口、 Comparator接口时具体讲解如何自定义比较规则。
第2课 ArrayList集合
ArrayList是List接口的一个实现类。 在后面的集合部分会有讲到。
一、什么是ArrayList集合
1.java.util.ArrayList类是大小可变的数组的实现,存储在内的数据称为元素。此类提供一些方法来操作内部存储的元素。 ArrayList中可不断添加元素,其大小也自动增长。
2.对于ArrayList来说,有一个尖括号代表泛型。
泛型:也就是装在集合当中的所有元素,全都是统一的什么类型。
注意:泛型只能是引用类型,不能是基本类型。
3.注意事项:
- 对于ArrayList集合来说,直接打印得到的不是地址值,而是内容。
- 如果内容是空,得到的是空的中括号:[]
二、ArrayList的使用
1.java.util.ArrayList<E>类:该类需要 import导入使后使用。
<E> ,表示一种指定的数据类型,叫做泛型。 E,取自Element(元素)的首字母。在出现 E 的地方,我们使用一种引用数据类型将其替换即可,表示我们将存储哪种引用类型的元素。 例如:
ArrayList<String>,ArrayList<Student>
2.构造方法
public ArrayList() :构造一个内容为空的集合。
基本格式如下:(JDK7开始,等号右边的尖括号中的内容可以省略)
ArrayList<String> list = new ArrayList<String>();
3.常用成员方法
- public boolean add(E e):将指定的元素添加到此集合的尾部。其中E是ArrayList指定的泛型,只能添加该数据类型的对象。返回值代表添加是否成功。(对于ArrayList集合来说,add添加动作一定是成功的,所以返回值可用可不用。但是对于其他集合来说,add添加动作不一定成功。)
- public E remove(int index):移除此集合中指定位置上的元素参数是索引编号,返回被删除的元素。
- public E get(int index):返回此集合中指定位置上的元素,参数是索引编号。
- public int size():返回此集合中的元素个数。通常用于遍历集合时,可以控制索引范围,防止越界。
import java.util.ArrayList;
public class ArrayListTest {
public static void main(String[] args) {
//创建集合对象
ArrayList<String> list = new ArrayList<>();
//添加元素
list.add("hello");
list.add("world");
list.add("java");
System.out.println(list);//[hello, world, java]
//public E get(int index):返回指定索引处的元素
System.out.println("get:" + list.get(0));//get:hello
System.out.println("get:" + list.get(1));//get:world
System.out.println("get:" + list.get(2));//get:java
//public int size():返回集合中的元素的个数
System.out.println("size:" + list.size());//size:3
//public E remove(int index):删除指定索引处的元素,返回被删除的元素
System.out.println("remove:" + list.remove(0));
//遍历输出
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
}
}
//输出结果:
//[hello, world, java]
//get:hello
//get:world
//get:java
//size:3
//remove:hello
//world
//java
三、 ArrayList存储基本数据类型
ArrayList对象不能存储基本类型,只能存储引用类型的数据。类似<int>不能写,但是存储基本数据类型对应的包装类型是可以的。
import java.util.ArrayList;
public class ArrayListBasicTest {
public static void main(String[] args) {
ArrayList<Integer> list = new ArrayList<>();
list.add(100);
list.add(200);
list.add(300);
System.out.println(list);//[100, 200, 300]
System.out.println("第三个元素为:" + list.get(2));
}
}
//输出结果:
//[100, 200, 300]
//第三个元素为:300
四、ArrayList集合的缺陷
1.ArrayList集合的底层是数据结构是数组。数组的特点是元素增删慢,查找快,由于日常开发中使用最多的功能为查询数据、遍历数据,所以ArrayList是最常用的集合。
2.如果对集合要做大量的增删操作时,使用ArrayList集合会使效率低下,并不合适。
第3课 toString方法、equals方法、Objects类
一、toString方法
1.toString()方法用于返回一个对象的字符串表示。通常,toString方法会返回一个“以文本方式表示”此对象的字符串。结果应是一个简明但易于读懂的信息表达式。建议所有子类都重写此方法。
2.如果不重写toString方法,则直接打印对象名时,输出的字符串是:
类名、at 标记符“@”和此对象哈希码的无符号十六进制表示(类似于内存地址值),即
getClass().getName() + '@' + Integer.toHexString(hashCode())
3.如果重写了toString方法,则打印对象名时,输出的字符串是重写toString方法后的返回的内容。例如:

二、toString方法总结
1.所有的类都默认自动继承了Object类
2.Object类中的toString方法返回的是类的名字和该对象哈希码组成的一个字符串
3.System.out.println(对象名);实际输出的是该对象的toString()方法所返回的字符串
即:System.out.println(对象名);等价于 System.out.println( 对象名.toString() )
4.为了实际需要,建议子类重写从父类Object继承的toString方法
三、equals方法
1.所有类都从Object类中继承了equlas方法
2.Object类中equals方法源代码如下:
public boolean equals(Object obj){
return this == obj;
}
用法:对象1.equals(对象2) 返回值为true或false
Object obj:可以传递任意的对象- == :比较运算符,返回的是一个布尔值 true/false
- 基本数据类型:比较的是值
- 引用数据类型:比较的是两个对象的地址值
- this是谁?哪个对象调用的方法,方法中的this就是那个对象;对象1调用的equals方法所以this就是对象1
- obj是谁?传递过来的参数对象2
3.Object中的equals方法是直接判断this和obj本身的值是否相等,即用来判断调用equals的对象和形参obj所引用的对象是否是同一对象,所谓同一对象就是指是内存中同一块存储单元,如果this和obj指向的是同一块内存对象,则返回true,如果this和obj指向的不是同一块内存,则返回false。
注意:即便是内容完全相等的两块不同的内存对象,也会返回false。
3.如果是同一块内存,则Object中的equals方法返回true,如果是不同的内存,则返回false。
注意: String、Date等类对equals方法进行了重写, 比较的是所指向的对象的内容,不再是比较两个对象的地址。
四、equals方法重写
假设现在有两个A类对象aa1 和 aa2,它们分别占用不同的内存,但是它们的内容都是一样的, 很多情况下,我们也应该认为aa1和aa2是相等的。
即:用同一个类构造的两个占用不同内存的对象,如果这两个对象虽然占用
不同的内存但是内存中的内值是一样的,则我们也应该认为这两个对象是相等的。
此时我们需要重写equals方法,重写equals方法存在以下麻烦:
1.隐含着一个多态
2.多态的弊端:无法使用子类特有的内容(属性和方法)
3.解决: 可以使用向下转型(强转)把obj类型转换为子类
重写equals方法如下,这是用IDEA直接生成的重写equals方法代码
public class Person {
private String name;
private int age;
@Override
public boolean equals(Object o) {
// 如果对象地址一样,则认为相同
if (this == o)
return true;
// 如果参数为空,或者类型信息不一样,则认为不同
if (o == null || getClass() != o.getClass())
return false;
// 多态:向下转型
Person person = (Person) o;
// 要求基本类型相等,并且将引用类型
// 交给java.util.Objects类的equals静态方法取用结果
return age == person.age && Objects.equals(name, person.name);
}
}
public class EqualsOverride {
public static void main(String[] args) {
Person p1 = new Person("小太阳",18);
Person p2 = new Person("小太阳",18);
System.out.println(p1.equals(p2));
}
}
//输出结果:true
五、Objects类
在刚才IDEA自动重写equals代码中,使用到了java.util.Objects类,那么这个类是什么呢?
在JDK7添加了一个Objects工具类,它提供了一些方法来操作对象,它由一些静态的实用方法组成,这些方法是null-save(空指针安全的)或null-tolerant(容忍空指针的),用于计算对象的hashcode、返回对象的字符串表示形式、比较两个对象。
在比较两个对象的时候,当有一个对象的引用为null时,Object的equals方法会抛出空指针异常,而Objects类中的equals方法就优化了这个问题。源码如下:
//Objects类的equals方法:
//对两个对象进行比较,防止空指针异常
public static boolean equals(Object a, Object b) {
return (a == b) || (a != null && a.equals(b));
}
第4课 String类
一、String类的equals方法
1.String类已经重写了Object类中的equals方法。String类的equals方法是用来判断两个对象的内容是否相等,Object类的equals方法是用来判断两个对象是否是同一个对象
2.一定要注意==与equals的区别。前者是比较
class StringEqualsTest {
public static void main(String[] args) {
// str1 和 str2 都指向了匿名对象"hello"
String str1 = "hello";
String str2 = "hello";
// 判断str1 和 str2自身的地址是否相等
if (str1 == str2) {
System.out.println("str1 == str2");
} else {
System.out.println("str1 != str2");
}
// str3 和 str4 很明显指向的是不同的对象
String str3 = new String("hello");
String str4 = new String("hello");
if (str3 == str4) {
System.out.println("str3 == str4");
} else {
System.out.println("str3 != str4");
}
// 判断str3与str4分别指向的对象的内容是否相等(String类会重写equals方法)
// 很明显是true
if (str3.equals(str4))
{
System.out.println("str3.equals(str4) == true");
}
}
}
//输出结果:
str1 == str2
str3 != str4
str3.equals(str4) == true

4.总结
str1 == str2 :比较的是str1存储的地址和str2存储的地址是否一样。
str3.equals(str4) : 比较的是str3指向的对象和str4指向的对象中,两个对象的中的内容是否相等。即使是两个不同的对象,只要他们保存的内容相同,就返回true。
二、String类的基本方法和判断方法
String类在实际开发中应用非常广泛,因此灵活地运用String类的方法非常重要。

public class StringTest {
public static void main(String[] args) {
String s1 = "helloXhh", s2 = "helloMyCute";
System.out.println(s1.charAt(5));//X,从0开始
System.out.println(s2.length());//11
System.out.println(s1.indexOf("xhh"));//-1
System.out.println(s1.indexOf("Xhh"));//5
System.out.println(s1.equals(s2));//false
System.out.println(s2.startsWith("hello"));//true
}
}
三、String类的字符串转换方法

1.String类的静态重载方法
public static String valueOf(任意变量)可以将任意基本数据类型转换成字符串。
public static xxx parseXxx(String s)可以将字符串参数转换为对应的xxx基本类型。
public class StringValueOfTest {
public static void main(String[] args) {
int i = 123;
String str = "456";
//生成一个新的对象,此对象将i转换成了字符串,赋值给str,i自身没有变化
str = String.valueOf(i);//将123转换成"123"然后赋值给str
System.out.println(i);//输出123
System.out.println(str + 100);//输出123100
//生成一个新的对象,此对象将str转换成了int,赋值给i,str自身没有变化
i = Integer.parseInt(str);//将"123"转换为123然后赋值给i
System.out.println(str);//输出123
System.out.println(i + 100);//输出223
}
}
2.字符串转换为字符数组、大小写转换
toCharArray()方法:将字符串转换为字符数组,转换为字符数组后,可以对字符串中间的单个字符进行操作。
toUpperCase()方法:将字符串中的字符都转换为大写
toLowerCase()方法:将字符串中的字符都转换为小写
public class StringTest {
public static void main(String[] args) {
String s1 = "helloXhh", s2 = "helloMyCute";
char[] charArray = s1.toCharArray();
for (int i = 0; i < charArray.length; i++) {
if(i != charArray.length - 1){
System.out.print(charArray[i]+",");
}else{
System.out.println(charArray[i]);
}
}
System.out.println(s2.toUpperCase());//HELLOMYCUTE
System.out.println(s2);//helloMyCute
System.out.println(s2.toLowerCase());//helloMyCute
}
}
输出结果://h,e,l,l,o,X,h,h
//HELLOMYCUTE
//helloMyCute
//hellomycute
3.字符串的替换和去除空格
replace(String s1 , String s2)方法:字符串替换,将字符串中所有的s1替换为s2
trim()方法:去除字符串的首尾空格
public class StringTest {
public static void main(String[] args) {
s3=" h e l l o w o r l d ";
System.out.println(s3.trim());//输出去除首尾空格的s3
System.out.println(s3.replace(" ",""));//将所有空格替换成空字符串
}
}
//输出结果:
//h e l l o w o r l d
//helloworld
4.字符串的截取与分割
substring(int n)方法:截取第n+1个字符到末尾的结果
substring(int n , int m)方法:截取第n+1个字符到第m个字符的结果
split()方法:将字符串按照某个字符进行分割
public class StringTest {
public static void main(String[] args) {
String s1 = "helloXhh", s4 = "2020-4-30";
System.out.println(s1.substring(5));//输出Xhh
System.out.println(s1.substring(0, 5));//输出hello
//字符串被拆分为2020,4,30存入字符串数组strArray
String[] strArray = s4.split("-");
System.out.println(strArray[2]);
}
}
//输出结果:Xhh
//hello
//30
第5课 StringBuilder类
一、概述
StringBuilder又称为可变字符序列,它是一个类似于 String 的字符串缓冲区,通过某些方法调用可以改变该序列的长度和内容。
StringBuilder是个字符串的缓冲区,即它是一个容器,容器中可以装很多字符串。并且能够对其中的字符串进行各种操作。
它的内部拥有一个数组用来存放字符串内容,进行字符串拼接时,直接在数组中加入新内容,而不会产生新的StringBuilder对象。StringBuilder会自动维护数组的扩容,默认16字符空间,超过会自动扩充。
二、String类和StringBuilder类的区别

1.如上图所示,如果对字符串进行拼接操作,每次拼接,都会构建一个新的String对象,既耗时,又浪费空间。为了解决这一问题,可以使用java.lang.StringBuilder类

2.StringBuilder类的对象内容是可以改变的,且StringBuilder类具有大量的修改字符串的方法,而String类没有修改字符串的方法。
三、StringBuilder类的构造方法
publicpublic
public class StringBuilder01Test {
public static void main(String[] args) {
//空参数构造方法
StringBuilder stringBuilderVoid = new StringBuilder();
System.out.println("字符串1 = " + stringBuilderVoid);
//带参数构造方法
StringBuilder stringBuilder = new StringBuilder("abc");
System.out.println("字符串2 = " + stringBuilder);
}
}
//输出结果:
//字符串1 =
//字符串2 = abc
四、 StringBuilder类的常用方法

public StringBuilderpublic String
1.append方法
append方法具有多种重载形式,可以接收任意类型的参数。任何数据作为参数都会将对应的字符串内容添加到StringBuilder中。
public class AppandTest {
public static void main(String[] args) {
//创建对象
StringBuilder builder = new StringBuilder();
//public StringBuilder append(任意类型)
//把builder的地址赋值给了builder2
StringBuilder builder2 = builder.append("hello");
//对比一下
System.out.println("builder:" + builder);
System.out.println("builder2:" + builder2);
System.out.println(builder == builder2); //true
// 可以添加 任何类型
builder.append("hello");
builder.append("world");
builder.append(true);
builder.append(100);
System.out.println("builder:" + builder);
//在我们开发中,会遇到调用一个方法后,返回一个对象的情况。然后使用返回的对象继续调用方法。
//这种时候,我们就可以把代码现在一起,如append方法一样,代码如下
//链式编程
builder.append("你好").append("中国").append(true).append(100);
System.out.println("builder:" + builder);
}
}
//输出结果:
//builder:hello
//builder2:hello
//true
//builder:hellohelloworldtrue100
//builder:hellohelloworldtrue100你好中国true100
备注:StringBuilder类已经重写了Object类的toString方法。
2.toString方法
StringBuilder和String可以相互转换:
String->StringBuilder:可以使用StringBuilder的构造方法
StringBuilder(String str) 构造一个字符串生成器,并初始化为指定的字符串内容。
StringBuilder->String:可以使用StringBuilder中的toString方法
public String toString():将当前StringBuilder对象转换为String对象。
public class StringBuilderToStringTest {
public static void main(String[] args) {
// 链式创建
StringBuilder sb = new StringBuilder("Hello").append("World").append("Java");
System.out.println(sb);
// 调用toString方法将sb转换为String类型
String str = sb.toString();
System.out.println(str); // HelloWorldJava
}
}
//输出结果:
//HelloWorldJava
//HelloWorldJava
3.insert和delete方法
insert(int offset , String str)方法:在第offset个字符后面插入字符串str
delete(int start , int end)方法:把下标从start开始到end-1结束的字符删除
public class StringBuilderTest {
public static void main(String[] args) {
StringBuilder sb = new StringBuilder();
sb.append("abc");
sb.append("123");
System.out.println("sb = " + sb); //sb = abc123
sb.insert(3, "--");
System.out.println("sb = " + sb); //sb = abc--123
sb.delete(2, 6); //把下标从2开始到6-1结束的字符删除
System.out.println("sb = " + sb); //sb = ab23
sb.reverse();
System.out.println("sb = " + sb); //sb = 32ba
String str = sb.toString();
System.out.printf("str = " + str); //str = 32ba
}
}
五、StringBuilder类注意事项
1.StringBuilder表示字符容器,其内容和长度可以随时修改。
2.String类重写了Object类中的equals方法,但是StringBuilder类没有重写。
3.String类的对象可以通过"+"号来连接字符串,而StringBuilder不行。
第6课 Date类 、DateFormat类、SimpleDateFormat类
一、Date类
1.java.util.Date类 表示特定的瞬间,精确到毫秒。
(1) 特定的瞬间:一个时间点,一刹那时间
2088-08-08 09:55:33:333 瞬间
2088-08-08 09:55:33:334 瞬间
2088-08-08 09:55:33:334 瞬间
(2) 1毫秒 = 千分之一秒 1000毫秒 = 1秒
(3) 毫秒值的作用:可以对时间和日期进行计算
2099-01-03 到 2088-01-01 中间一共有多少天
可以日期转换为毫秒进行计算,计算完毕,在把毫秒转换为日期
2.Date类拥有多个构造函数,只是部分已经过时,但是其中有未过时的构造函数可以把毫秒值转成日期对象。
- public Date() :分配Date对象并初始化此对象,以表示分配它的时间(精确到毫秒)。
- public Date(long date) :分配Date对象并初始化此对象,以表示自从标准基准时间(称为“历元(epoch)”,即1970年1月1日00:00:00 GMT)以来的指定毫秒数。
tips: 由于我们处于东八区,所以我们的基准时间为1970年1月1日8时0分0秒。
3.简单来说:使用无参构造,可以自动设置当前系统时间的毫秒时刻;指定long类型的构造参数,可以自定义毫秒时刻。例如:
import java.util.Date;
public class DateTest {
public static void main(String[] args) {
// 创建日期对象,把当前的时间转换成日期对象
//Thu Apr 16 08:21:12 CST 2020
System.out.println(new Date());
// 创建日期对象,把当前的毫秒值转成日期对象
// Thu Jan 01 08:00:00 CST 1970
System.out.println(new Date(0L));
}
}
tips:在使用println方法时,会自动调用Date类中的toString方法。Date类对Object类中的toString方法进行了覆盖重写,所以结果为指定格式的字符串。
4. Date类的常用方法
public long getTime() 把日期对象转换成对应的时间毫秒值。
import java.util.Date;
public class DateTest_1 {
public static void main(String[] args) {
demo01();
}
/*
long getTime() 把日期转换为毫秒值(相当于System.currentTimeMillis()方法)
返回自 1970 年 1 月 1 日 00:00:00 GMT 以来此 Date 对象表示的毫秒数。
*/
private static void demo01() {
Date date = new Date();
long time = date.getTime();
//Thu Apr 16 09:00:57 CST 2020
System.out.println(date);
//1586998528537
System.out.println(time);
//1586998528538
System.out.println(System.currentTimeMillis());
}
}
二、DateFormat类
使用Date类时,在程序中打印Date对象所输出的当前时间都是以默认的英文格式输出的,如果要将Date对象表示的日期以指定的格式输出,例如输出中文格式的时间,就需要用到DateFormat类。
java.text.DateFormat 是日期/时间格式化子类的抽象类,我们通过这个类可以帮我们完成日期和文本之间的转换,也就是可以在Date对象与String对象之间进行来回转换。
1.DataFormat类的静态方法
DateFormat是一个抽象类,不能被直接实例化,但它提供了一系列的静态方法来获取DateFormat类的实例对象,并能调用其他相应的方法进行操作。

上表中列出了DateFormat类的四个静态方法,这四个静态方法能用于获得DateFormat类的实例对象(这些对象是DateFormat类的子类SimpleDateFormat类的对象),每种方法返回的对象都具有不同的作用,它们可以分别对日期或者时间部分进行格式化。
2. DateFormat类的常量
DateFormat类中定义了许多常量,有四个常量值是用于作为参数传递给方法的,包括FULL、LONG、MEDIUM和SHORT。FULL常量用于表示完整格式,LONG常量用于表示长格式,MEDIUM常量用于表示普通格式,SHORT常量用于表示短格式。以下代码中用到了format(Date date)方法,后面会讲到这个方法的。
import java.text.DateFormat;
import java.util.Date;
public class DateFormatTest {
public static void main(String[] args) {
Date date = new Date();
//创建完整格式(FULL)的日期格式化对象
DateFormat fullFormat = DateFormat.getDateInstance(DateFormat.FULL);
//长格式(LONG)日期
DateFormat longFormat = DateFormat.getDateInstance(DateFormat.LONG);
//创建普通格式(MEDIUM)的日期和时间格式化对象
DateFormat mediumFormat = DateFormat.getDateTimeInstance(DateFormat.MEDIUM, DateFormat.MEDIUM);
//短格式(MEDIUM)日期和时间
DateFormat shortFormat = DateFormat.getDateTimeInstance(DateFormat.SHORT, DateFormat.SHORT);
System.out.println("当前日期的完整格式为:" + fullFormat.format(date));
System.out.println("当前日期的长格式为:" + longFormat.format(date));
System.out.println("当前日期和时间的普通格式为:" + mediumFormat.format(date));
System.out.println("当前日期和时间的短格式为:" + shortFormat.format(date));
}
}
//输出结果:
//当前日期的完整格式为:2020年5月6日星期三
//当前日期的长格式为:2020年5月6日
//当前日期和时间的普通格式为:2020年5月6日 下午11:12:37
//当前日期和时间的短格式为:2020/5/6 下午11:12
三、SimpleDateFormat类
1.DateFormat类是一个抽象类,无法直接创建对象使用。如果我们需要自定义格式化的字符串,可以使用DateFormat类的子类 SimpleDateFormat类来创建对象。
- 格式化:按照指定的格式,从Date对象转换为String对象。(日期 -> 文本)
- 解析:按照指定的格式,从String对象转换为Date对象。(文本-> 日期)
2. SimpleDateFormat 类的成员方法
以下两个方法实际上来自 DateFormat类,只是被SimpleDateFormat类继承了。
String format(Date date):按照指定的模式,把Date日期,格式化为符合模式的字符串
Date parse(String source):把符合模式的字符串,解析为Date日期
3. SimpleDateFormat 类的构造方法
这个类需要一个模式(格式)来指定格式化或解析的标准。构造方法为:
public SimpleDateFormat(String pattern):用给定的模式和默认语言环境的日期格式符号构造SimpleDateFormat。
参数pattern代表日期时间的自定义格式。 常用的格式规则如下:
| 标识字母(区分大小写) | 含义 |
|---|---|
| y | 年 |
| M | 月 |
| d | 日 |
| H | 时 |
| m | 分 |
| s | 秒 |
更详细的格式规则,可以参考SimpleDateFormat类的API文档。
(1)写对应的模式,会把模式替换为对应的日期和时间
"yyyy-MM-dd HH:mm:ss"
注意:模式中的字母不能更改,连接模式的符号可以改变
"yyyy年MM月dd日 HH时mm分ss秒"
(2)创建SimpleDateFormat对象的代码如:
import java.text.DateFormat;
import java.text.SimpleDateFormat;
public class SimpleDateFormatTest {
public static void main(String[] args) {
DateFormat sdf = new SimpleDateFormat("yyyy年MM月dd日 HH时mm分ss秒");
}
}
4. SimpleDateFormat 类的成员方法 使用步骤
(1) public String format(Date date):将Date对象格式化为字符串。
使用步骤:
- 创建SimpleDateFormat对象,构造方法中传递指定的模式
- 调用SimpleDateFormat对象中的方法format(Date date),按照构造方法中指定的模式,把Date日期格式化为符合模式的字符串(文本)
import java.text.DateFormat;
import java.text.SimpleDateFormat;
import java.util.Date;
public class SimpleDateFormatTest {
public static void main(String[] args) {
demo01();
}
private static void demo01() {
//步骤1
SimpleDateFormat sdf = new SimpleDateFormat("yyyy年MM月dd日 HH时mm分ss秒");
Date date = new Date();
//步骤2
String d = sdf.format(date);
System.out.println(date);//Thu Apr 16 09:47:27 CST 2020
System.out.println(d);//2020年04月16日 09时47分27秒
}
}
(2) public Date parse(String source):将字符串解析为Date对象。
使用步骤:
- 创建SimpleDateFormat对象,构造方法中传递指定的模式
- 调用SimpleDateFormat对象中的方法parse(String source) ,把符合构造方法中模式的字符串,解析为Date日期
注意事项:
public Date parse(String source) throws ParseException
parse方法声明了一个异常叫ParseException,必须进行处理!
如果字符串和构造方法的模式不一样,那么程序就会抛出此异常
调用一个抛出了异常的方法,就必须的处理这个异常,要么throws继续抛出这个异常,要么try catch自己处理
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
public class SimpleDateFormatTest {
public static void main(String[] args) {
try {
demo02();
}catch (ParseException e){
System.out.println("格式错误");
}
}
private static void demo02() throws ParseException {
//步骤1
SimpleDateFormat sdf = new SimpleDateFormat("yyyy年MM月dd日 HH时mm分ss秒");
//步骤2
Date date = sdf.parse("2088年08月08日 15时51分54秒");
System.out.println(date);
System.out.println(date.getTime());
}
}
//输出结果
//Sun Aug 08 15:51:54 CST 2088
//3742789914000
第7课 Calendar类
一、Calendar类
1.java.util.Calendar是日历类,也是一个抽象类,在Date后出现,替换掉了许多Date的方法。该类将所有可能用到的时间信息封装为静态成员变量,方便获取。日历类就是方便获取各个时间属性的。
2.Calendar类是抽象类,无法直接创建对象使用,里边有一个静态方法叫getInstance(),该方法返回了Calendar类的子类对象
static Calendar getInstance() 方法:使用默认时区和语言环境获得一个日历。
创建Calendar类的对象:
Calendar c = Calendar.getInstance();
二、 Calendar类的常用方法
1.成员方法
public int get(int field):返回给定日历字段的值。
public void set(int field, int value):将给定的日历字段设置为给定值。
public void set(int year, int month, int date):设置Calendar对象的年月日三个字段的值。
public void set(int year, int month, int date, int hourOfDay, int minute, int second): 设置Calendar对象的年月日时分秒六个字段的值。
public abstract void add(int field, int amount):根据日历的规则,为给定的日历字段添加或减去指定的时间量。
public Date getTime():返回一个表示此Calendar时间值(从历元到现在的毫秒偏移量)的Date对象。
2.成员方法的参数列表
- int field:日历类的字段,可以使用Calendar类的静态成员变量获取
public static final int YEAR = 1; 年
public static final int MONTH = 2; 月(从0开始,可以+1使用) - public static final int DATE = 10; 日
public static final int DAY_OF_MONTH = 5;月中的某一天
public static final int HOUR = 10; 时(12小时制) - public static final int HOUR_OF_DAY = 23; 时(24小时制)
public static final int MINUTE = 12; 分
public static final int SECOND = 13; 秒 - public static final int DAY_OF_WEEK = 4 周中的天(周几,周日为1,可以-1使用)
三、Calendar类的常用方法的使用
1.get方法
public int get(int field):返回给定日历字段的值。
int field:传递指定的日历字段(YEAR,MONTH…)
返回值:日历字段代表的具体的值
import java.util.Calendar;
public class CalendarTest {
public static void main(String[] args) {
getDate();
}
private static void getDate() {
// 创建Calendar对象
Calendar cal = Calendar.getInstance();
// 设置年
int year = cal.get(Calendar.YEAR);
// 设置月
int month = cal.get(Calendar.MONTH) + 1;
// 设置日
int dayOfMonth = cal.get(Calendar.DAY_OF_MONTH);
System.out.print(year + "年" + month + "月" + dayOfMonth + "日");
}
}
//输出结果:
//2020年4月16日
2.set方法
public void set(int field, int value):将给定的日历字段设置为给定值。
参数:
int field:传递指定的日历字段(YEAR,MONTH…)
int value:给指定字段设置的值
import java.util.Calendar;
public class CalendarTest {
public static void main(String[] args) {
setDate();
}
private static void setDate() {
//使用getInstance方法获取Calendar对象
Calendar c = Calendar.getInstance();
//设置年为2099
c.set(Calendar.YEAR,2099);
//设置月为9月
c.set(Calendar.MONTH,9);
//设置日9日
c.set(Calendar.DATE,9);
//同时设置年月日,可以使用set的重载方法
c.set(8888,8,8);
System.out.println(c.get(Calendar.YEAR)+"年"+c.get(Calendar.MONTH)+"月"+c.get(Calendar.DATE)+"日");
}
}
//输出结果:8888年8月8日
3.add方法
public abstract void add(int field, int amount):根据日历的规则,为给定的日历字段添加或减去指定的时间量。
把指定的字段增加/减少指定的值
参数:
int field:传递指定的日历字段(YEAR,MONTH…)
int amount:增加/减少指定的值
正数:增加
负数:减少
例如:
Calendar c = Calendar.getInstance(); //把年增加2年 c.add(Calendar.YEAR,2); //把月份减少3个月 c.add(Calendar.MONTH,-3); //把天数增加100天 c.add(Calendar.DATE,100);
4.getTime方法
Calendar中的getTime方法并不是获取毫秒时刻,而是拿到对应的Date对象。
public Date getTime():返回一个表示此Calendar时间值(从历元到现在的毫秒偏移量)的Date对象。
把日历对象,转换为日期对象
import java.text.DateFormat;
import java.text.SimpleDateFormat;
import java.util.Calendar;
import java.util.Date;
public class CalendarTest {
public static void main(String[] args) {
calenderTrans();
}
private static void calenderTrans() {
Calendar cal = Calendar.getInstance();
Date date = cal.getTime();
System.out.println(date);
DateFormat df = new SimpleDateFormat("yyyy年MM月dd日 HH点mm分ss秒");
System.out.println(df.format(date));
}
}
//输出结果:
//Thu Apr 16 11:28:54 CST 2020
//2020年04月16日 11点28分
第8课 JDK8新增的日期和时间类、DateTimeFormatter类
一、JDK8新增的日期和时间类
为了满足更多的需求,JDK8新增了一个java.time包,这个包包含了更多的日期和时间操作类。
主要涉及的类型有:
- 本地日期和时间:
LocalDateTime,LocalDate,LocalTime; - 带时区的日期和时间:
ZonedDateTime; - 时刻:
Instant; - 时区:
ZoneId,ZoneOffset; - 时间间隔:
Duration。

使用举例:
import java.time.*;
public class JDK8TimeTest {
public static void main(String[] args) {
//Clock类
Clock clock = Clock.systemUTC();
//获取到的标准时间:2020-05-07T01:42:31.606580Z
System.out.println("获取到的标准时间:" + clock.instant());
//获取到的毫秒数:1588815751611
System.out.println("获取到的毫秒数:" + clock.millis());
//DayOfWeek类
System.out.println(DayOfWeek.WEDNESDAY);//WEDNESDAY
//Duration类
Duration duration = Duration.ofDays(1);
//一天等于24小时
System.out.println("一天等于" + duration.toHours() + "小时");
//一天等于1440分钟
System.out.println("一天等于" + duration.toMinutes() + "分钟");
//一天等于86400秒(JDK8没有toSeconds方法)
//System.out.println("一天等于" + duration.toSeconds() + "秒");//JDK9
System.out.println("一天等于" + duration.getSeconds() + "秒");//JDK8
//Instant类
Instant instant = Instant.now();
//当前国际标准时间:2020-05-07T01:42:31.619580800Z
System.out.println("当前国际标准时间:" + instant);
//当前国际标准时间的一小时后:2020-05-07T02:42:31.619580800Z
System.out.println("当前国际标准时间的一小时后:" + instant.plusSeconds(3600));
//当前国际标准时间的一小时前:2020-05-07T00:42:31.619580800Z
System.out.println("当前国际标准时间的一小时前:" + instant.minusSeconds(3600));
//LocalDate类
LocalDate localDate = LocalDate.now();
System.out.println("当前日期:" + localDate);//2020-05-07
//LocalTime类
LocalTime localTime = LocalTime.now();
System.out.println("当前时间:" + localTime);//09:42:31.629581300
//LocalDateTime类
LocalDateTime localDateTime = LocalDateTime.now();
//当前日期和时间:2020-05-07T09:42:31.630581400
System.out.println("当前日期和时间:" + localDateTime);
//时间增加
LocalDateTime ldt2 = localDateTime.plusDays(1).plusHours(3).plusMinutes(30);
System.out.println("在当前日期和时间基础上,加上1天3小时30分钟:");
System.out.println(ldt2);//2020-05-08T13:12:31.630581400
//Month类
System.out.println(Month.MAY);//MAY
//MonthDay类
MonthDay monthDay = MonthDay.now();
System.out.println("当前的月份和日期:" + monthDay);//--05-07
//Year类
System.out.println("当前的年份:" + Year.now());//2020
//YearMonth类
System.out.println("当前年份和月份:" + YearMonth.now());//2020-05
//ZoneId类
System.out.println("当前的时区是:" + ZoneId.systemDefault());//Asia/Shanghai
}
}
二、DateTimeFormatter类
1.使用旧的Date对象时,我们用SimpleDateFormat进行格式化 (日期 -> 文本) 显示。使用新的LocalDateTime或ZonedLocalDateTime时,我们要进行格式化显示,就要使用DateTimeFormatter。
2.创建DateTimeFormatter对象,完成日期、时间格式化(日期 -> 文本)
(1)通过传入格式化字符串实现(推荐)
//创建日期和时间对象
LocalDateTime localDateTime = LocalDateTime.now();
//通过传入格式化字符串获取DateTimeFormatter对象
DateTimeFormatter customizeFormatter = DateTimeFormatter.ofPattern("yyyy年MM月dd日 HH时mm分ss秒");
//调用DateTimeFormatter的format方法,完成格式化
String str = customizeFormatter.format(localDateTime);
System.out.println(str);
//也可以调用LocalDateTime的format方法,完成格式化
str = localDateTime.format(customizeFormatter);
System.out.println(str);
//输出结果:
//2020年05月07日 10时25分38秒
//2020年05月07日 10时25分38秒
使用DateTimeFormatter对日期时间完成格式化与使用SimpleDateFormat完成格式化方法一致。其中前者既可以由DateTimeFormatter对象调用format方法,也可以由日期时间对象调用format方法。下面是用SimpleDateFormat对象完成格式化。
//创建Date对象
Date date = new Date();
//创建SimpleDateFormat对象并传入格式化字符串
SimpleDateFormat sdf = new SimpleDateFormat("yyyy年MM月dd日 HH时mm分ss秒");
//调用SimpleDateFormat对象的format方法
String d = sdf.format(date);
//下面这么写是错误的
//d = date.format(format);//Date对象没有format方法
System.out.println(date);//Thu Apr 16 09:47:27 CST 2020
System.out.println(d);//2020年04月16日 09时47分27秒
(2)使用不同风格的枚举值来创建DateTimeFormatter对象。在FormatStyle类中定义了FULL、LONG、MEDIUM和SHORT四个枚举值,它们表示日期和时间的不同风格。(别用,不推荐,我用了直接报异常不知道什么贵)
DateTimeFormatter dtf = DateTimeFormatter.ofLocalizedDateTime(FormatStyle.LONG);
(3)使用静态常量创建DateTimeFormatter对象。在DateTimeFormatter类中包含大量的静态常量,如BASIC_ ISO_ DATE.ISO_ LOCAL_ DATE、ISO_ LOCAL_ TIME等,通过这些静态常量都可以获取DateTimeFormatter实例。(不推荐)
DateTimeFormatter format = DateTimeFormatter.ISO_LOCAL_DATE.format(date);
3. 使用DateTimeFormatter将字符串解析成日期、时间对象
若要将字符串通过DateTimeormatter对象的格式化规则,将字符串解析为日期和时间。需要使用日期和时间对象的parse方法实现。
parse(被解析的字符串, DateTimeormatter对象)
import java.time.*;
import java.time.format.*;
public class DateTimeFormatterParseTest {
public static void main(String[] args) {
// 定义两种日期格式的字符串
String str1 = "2018-01-27 12:38:36";
String str2 = "2018年01月29日 15时01分20秒";
// 定义解析所用的格式器
DateTimeFormatter formatter1 = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
DateTimeFormatter formatter2 = DateTimeFormatter.ofPattern("yyyy年MM月dd日 HH时mm分ss秒");
// 使用LocalDateTime的parse()方法执行解析
LocalDateTime localDateTime1 = LocalDateTime.parse(str1, formatter1);
LocalDateTime localDateTime2 = LocalDateTime.parse(str2, formatter2);
// 输出结果
System.out.println(localDateTime1);//2018-01-27T12:38:36
System.out.println(localDateTime2);//2018-01-29T15:01:20
}
}
第9课 System类
java.lang.System类中提供了大量的静态方法和静态属性,该类不能被实例化,并且被final修饰而不可以被继承。可以获取与系统相关的信息或系统级操作,在System类的API文档中,常用的方法有:

public static long currentTimeMillis()方法:返回以毫秒为单位的当前时间。
public static void arraycopy(Object src, int srcPos, Object dest, int destPos, int length)方法 :将数组中指定的数据拷贝到另一个数组中。
public static Properties getProperties()方法:获取当前操作系统属性的信息
一、currentTimeMillis方法
currentTimeMillis方法就是获取当前系统时间与1970年01月01日00:00点之间的毫秒差值
可以用于计时器
public class SystemTest {
public static void main(String[] args) {
currentTimeMillisMethod();
}
private static void currentTimeMillisMethod() {
double beginTime = System.currentTimeMillis();
for (int i = 0; i < 10000; i++){
System.out.println(i);
}
double endTime = System.currentTimeMillis();
System.out.println("程序执行时间:"+(endTime-beginTime)/1000+"秒");
}
//输出结果:
//程序执行时间:0.033秒
二、arraycopy方法
1.public static void arraycopy(Object src, int srcPos, Object dest, int destPos, int length):将数组中指定的数据拷贝到另一个数组中。
2. 数组的拷贝动作是系统级的,性能很高。System.arraycopy方法具有5个参数,含义分别为:
| 参数序号 | 参数名称 | 参数类型 | 参数含义 |
|---|---|---|---|
| 1 | src | Object | 源数组 |
| 2 | srcPos | int | 源数组索引起始位置 |
| 3 | dest | Object | 目标数组 |
| 4 | destPos | int | 目标数组索引起始位置 |
| 5 | length | int | 复制元素个数 |
3.举例:将src数组中前3个元素,复制到dest数组的最后3个位置上
import java.util.Arrays;
public class SystemTest {
public static void main(String[] args) {
arraycopyMethod();
}
private static void arraycopyMethod() {
int[] src = new int[]{1,2,3,4,5};
int[] dest = new int[]{6,7,8,9,10};
//src从0开始索引,dest从dest.length-3的位置开始索引
System.arraycopy(src,0,dest,dest.length-3,3);
System.out.println("dest = "+ Arrays.toString(dest));
}
}
//输出结果:
//dest = [6, 7, 1, 2, 3]
三、 getProperties方法
System类的getProperties()方法用于获取当前系统的全部属性,该方法会返回一个Properties对象,其中封装了系统的所有属性,这些属性是以键值对的形式存在。包括了虚拟机版本号、用户国家、操作系统版本等。若要具体获取某个key(属性名)的属性,学到集合(Collection)的时候再讲。
public class PropertiesTest {
public static void main(String[] args) {
Properties properties = System.getProperties();
System.out.println(properties);
}
}
输出结果:
//{java.specification.version=13, sun.cpu.isalist=amd64, sun.jnu.encoding=GBK, java.class.path=D:\Development\Developer\Java\Java_Projects\J2SECourse\bin, java.vm.vendor=Oracle Corporation, sun.arch.data.model=64, user.variant=, java.vendor.url=https://java.oracle.com/, java.vm.specification.version=13, os.name=Windows 7, sun.java.launcher=SUN_STANDARD, user.country=CN, sun.boot.library.path=D:\Development\jdk-13\bin, sun.java.command=daily.apr0430.PropertiesTest, jdk.debug=release, sun.cpu.endian=little, user.home=C:\Users\AnonyEast, user.language=zh, java.specification.vendor=Oracle Corporation, java.version.date=2019-09-17, java.home=D:\Development\jdk-13, file.separator=\, java.vm.compressedOopsMode=Zero based, line.separator=
, java.vm.specification.vendor=Oracle Corporation, java.specification.name=Java Platform API Specification, user.script=, sun.management.compiler=HotSpot 64-Bit Tiered Compilers, java.runtime.version=13+33, user.name=AnonyEast, path.separator=;, os.version=6.1, java.runtime.name=Java(TM) SE Runtime Environment, file.encoding=UTF-8, java.vm.name=Java HotSpot(TM) 64-Bit Server VM, java.vendor.url.bug=https://bugreport.java.com/bugreport/, java.io.tmpdir=C:\Users\ANONYE~1\AppData\Local\Temp\, java.version=13, user.dir=D:\Development\Developer\Java\Java_Projects\J2SECourse, os.arch=amd64, java.vm.specification.name=Java Virtual Machine Specification, sun.os.patch.level=Service Pack 1, java.library.path=D:\Development\jdk-13\bin;C:\Windows\Sun\Java\bin;C:\Windows\system32;C:\Windows;C:\Windows\system32;C:\Windows;C:\Windows\System32\Wbem;C:\Windows\System32\WindowsPowerShell\v1.0\;F:\YANGDONG\MinGW\bin\;D:\Development\LLVM\bin;C:\Program Files (x86)\NVIDIA Corporation\PhysX\Common;D:\Development\LLVM\bin;D:\Development\Microsoft VS Code\bin;D:\Development\jdk-13\bin;;., java.vm.info=mixed mode, sharing, java.vendor=Oracle Corporation, java.vm.version=13+33, sun.io.unicode.encoding=UnicodeLittle, java.class.version=57.0}
第10课 包装类
一、概述
Java提供了两个类型系统,基本类型与引用类型,使用基本类型在于效率,然而很多情况,会创建对象使用,因为对象可以做更多的功能,如果想要我们的基本类型像对象一样操作,就可以使用基本类型对应的包装类,如下:
| 基本类型 | 对应的包装类(位于java.lang包中) |
| byte | Byte |
| short | Short |
| int | Integer |
| long | Long |
| float | Float |
| double | Double |
| char | Character |
| boolean | Boolean |
注意事项:
1.所有的包装类都是final修饰的,也就是它们都是无法被继承和重写的。
2.包装类的继承关系:除了Boolean、Character类型直接继承Object类,其他:Byte、Short、Integer、Long、Float、Double都是继承Object的子类Number类。
二、装箱与拆箱
基本类型与对应的包装类对象之间,来回转换的过程称为”装箱“与”拆箱“:
- 装箱:基本类型 --> 对应的包装类对象。
- 拆箱:包装类对象 --> 对应的基本类型。
1.装箱方法
把基本类型的数据,包装到包装类中(基本类型的数据-->包装类)
构造方法:
- Integer(int value) 构造一个新分配的 Integer 对象,它表示指定的 int 值。
- Integer(String s) 构造一个新分配的 Integer 对象,它表示 String 参数所指示的 int 值。传递的字符串,必须是基本类型的字符串,否则会抛出异常。 "100" 正确 ,"a" 抛异常。
静态方法:
- static Integer valueOf(int value) 返回一个表示指定的 int 值的 Integer 对象。
- static Integer valueOf(String s) 返回保存指定的 String 的值的 Integer 对象。
2.拆箱方法
在包装类中取出基本类型的数据(包装类->基本类型的数据)
成员方法:int intValue() 以 int 类型返回该 Integer 对象的值。
public class Demo01Integer {
public static void main(String[] args) {
//装箱:把基本类型的数据,包装到包装类中(基本类型的数据->包装类)
//构造方法
Integer in1 = new Integer(1);//方法上有横线,说明方法过时了
//打印的对象却输出了1 说明重写了toString方法
System.out.println(in1);
Integer in2 = new Integer("2");
System.out.println(in2);//2
//静态方法
Integer in3 = Integer.valueOf(3);
System.out.println(in3);
//Integer in4 = Integer.valueOf("a");//NumberFormatException数字格式化异常
Integer in4 = Integer.valueOf("4");
System.out.println(in4);//4
//拆箱:在包装类中取出基本类型的数据(包装类->基本类型的数据)
int i = in1.intValue();//1
System.out.println(i);//1
}
}
//输出结果:
//1
//2
//3
//4
//1
三、自动装箱与自动拆箱
由于我们经常要做基本类型与包装类之间的转换,从Java 5(JDK 1.5)开始,基本类型与包装类的装箱、拆箱动作可以自动完成。
Integer i = 4;//自动装箱。相当于Integer i = Integer.valueOf(4); i = i + 5;//等号右边:将i对象转成基本数值(自动拆箱) i.intValue() + 5; //加法运算完成后,再次装箱,i = i.intValue() + 5 = 9,把基本数值转成对象。
四、基本类型与字符串类型之间的相互转换
1.装箱:基本类型->字符串(String) 三种方法
- (1)基本类型的值+"" 最简单的方法(工作中常用)
- (2)包装类的静态方法toString(参数),不是Object类的toString(),两者是重载关系
- static String toString(int i) 返回一个表示指定整数的 String 对象。
- (3)String类的静态方法valueOf(参数)
- static String valueOf(int i) 返回 int 参数的字符串表示形式。
2.拆箱:字符串(String)->基本类型
除了Character类之外,其他所有包装类都具有parseXxx(String s)静态方法可以将字符串参数转换为对应的基本类型:
public static bytepublic static shortpublic static intpublic static longpublic static floatpublic static doublepublic static boolean
//基本类型->字符串(String)
int i1 = 100;
String s1 = i1 + "";
System.out.println(s1+200);//输出100200
String s2 = Integer.toString(100);
System.out.println(s2+200);//输出100200
String s3 = String.valueOf(100);
System.out.println(s3+200);//输出100200
//字符串(String)->基本类型
int i = Integer.parseInt(s1);//将s1转换为int类型
System.out.println(i+10);//输出110,而不是10010
int a = Integer.parseInt("a");//抛NumberFormatException异常
五、两个包装类引用相等性
在Java中,“==”符号判断的内存地址所对应的值得相等性,具体来说,基本类型判断值是否相等,引用类型判断其指向的地址是否相等。看看下面的代码,两种类似的代码逻辑,但是得到截然不用的结果。
Integer a1 = 111; Integer a2 = 111; System.out.println(a1 == a2); // true Integer b1 = 222; Integer b2 = 222; System.out.println(b1 == b2); // false
由于111属于[-128, 127]集合范围内,这是默认的可缓存范围,所有valueOf()每次都会取出同一个Integer对象, 故第一个“==” 判断结果为true;
但是222不属于这个集合范围,所以valueOf() 每次都会创建一个新的Integer对象,由于两个新创建的对象的地址不一样,所以第二个判断结果为false。
第11课 Runtime类、Math类、Random类
一、Runtime类
Runtime类用于表示Java虚拟机运行时的状态,它用于封装Java虛拟机进程。每次使用java命令启动Java虛拟机时都会对应一个Runtime实例,并且只有一个实例,应用程序会通过该实例与其运行时的环境相连。Runtime类没有构造方法,因此应用程序不能new自己的Runtime实例,若想在程序中获得一个Runtime实例,可以通过getRuntime()方法获取与之相关的Runtime对象。
1.常用方法
- getRuntime():该方法用于返回当前应用程序的运行环境对象。
- exec(String command):该方法用于根据指定的路径执行对应的可执行文件,相当于调用cmd命令。此方法会返回一个Process对象,该对象表示操作系统的一个进程,通常是被执行文件的进程,通过Process对象可以对这个进程进行管理。
- freeMemory():该方法用于返回Java虚拟机中的空闲内存量,以字节为单位。
- maxMemory():该方法用于返回Java虚拟机试图使用的最大内存量。
- totalMemory():该方法用于返回Java虚拟机中的内存总量。
(1)exec方法的使用
调用exec方法时,必须处理可能抛出的IOException异常,因此要在方法声明处要写上throws IOException。以下代码会启动notepad.exe程序。
import java.io.IOException;
public class RuntimeTest {
public static void main(String[] args) throws IOException {
//获取运行环境对象
Runtime runtime = Runtime.getRuntime();
//启动notepad.exe(记事本)
Process process = runtime.exec("notepad.exe");
}
}
(2) freeMemory、maxMemory、 totalMemory 方法的使用
import java.io.IOException;
public class RuntimeTest {
public static void main(String[] args) throws IOException {
Runtime runtime = Runtime.getRuntime();
System.out.println("Java虚拟机中的空闲内存量:" + runtime.freeMemory() / 1024 / 2014 + "MB");
System.out.println("Java虚拟机试图使用的最大内存量:" + runtime.maxMemory() / 1024 / 2014 + "MB");
System.out.println("Java虚拟机中的内存总量:" + runtime.totalMemory() / 1024 / 2014 + "MB");
}
}
//输出结果:
//Java虚拟机中的空闲内存量:96MB
//Java虚拟机试图使用的最大内存量:1554MB
//Java虚拟机中的内存总量:97MB
二、Math类
- Math类是一个工具类,主要用于完成复杂的数学运算,如求绝对值、三角函数、指数运算等。
- 由于Math类的构造方法被定义成private,因此无法创建Math类的对象。
- Math类中的所有方法都是静态方法,可以直接通过类名来调用它们。
- 除静态方法外,Math类中还有两个静态常量PI和E,分别代表数学中的π和e。
具体用法看代码吧
public class MathTest {
public static void main(String[] args) {
//三角函数和角度问题
System.out.println("sin(π/2):" + Math.sin(Math.PI / 2));
System.out.println("sin(90°):" + Math.signum(90));
System.out.println("弧度转角度:" + Math.toDegrees(Math.PI / 2));
System.out.println("角度转弧度:" + Math.toRadians(90));
//科学计算
System.out.println("4开方:" + Math.sqrt(4));
System.out.println("-10.312的绝对值:" + Math.abs(-10.312));
System.out.println("2的8次方:" + Math.pow(2, 8));
//四舍五入
System.out.println("3.1四舍五入:" + Math.round(3.1));
System.out.println("3.1向上取整:" + Math.ceil(3.1));
System.out.println("3.1向下取整:" + Math.floor(3.1));
//最大最小值
System.out.println("1,2中的最大值:" + Math.max(1, 2));
System.out.println("1,2中的最小值:" + Math.min(1, 2));
//随机数
System.out.println("产生double随机数(0~1):" + Math.random());
//对数运算
System.out.println("ln(10):" + Math.log(10));//底数为e
System.out.println("lg(10):" + Math.log10(10));//底数为10
}
}
//输出结果:
//sin(π/2):1.0
//sin(90°):1.0
//弧度转角度:90.0
//角度转弧度:1.5707963267948966
//4开方:2.0
//-10.312的绝对值:10.312
//2的8次方:256.0
//3.1四舍五入:3
//3.1向上取整:4.0
//3.1向下取整:3.0
//1,2中的最大值:2
//1,2中的最小值:1
//产生double随机数(0~1):0.07615748489834284
//ln(10):2.302585092994046
//lg(10):1.0
三、Random类
java.util.Random,此类可以在指定的范围内产生随机数字。
1.Random类的构造方法

2.Random类的常用方法

若要生成1-n之间整数,使用以下代码
import java.util.Random;
public class RandomTest {
public static void main(String[] args) {
int n = 50;
// 创建对象
Random r = new Random();
// 获取随机数
int number = r.nextInt(n) + 1;
// 输出随机数
System.out.println("number:" + number);
}
}
第12课 集合、Collection接口
一、集合概述
1.集合是Java中提供的一种容器,可以用来存储多个数据。
集合和数组既然都是容器,它们有啥区别呢?
- 数组的长度是固定的。集合的长度是可变的。
- 数组中存储的是同一类型的元素,可以存储基本数据类型值。集合存储的都是对象,而且对象的类型可以不一致。在开发中一般当对象多的时候,使用集合进行存储。
2.学习集合的目标
- 会使用集合存储数据
- 会遍历集合,把数据取出来
- 掌握每种集合的特性
3.集合框架的学习方式
- 学习顶层:学习顶层接口/抽象类中共性的方法,所有的子类都可以使用。共性就是实现了同一个接口/抽象类的意思。
- 使用底层:顶层不是接口就是抽象类,无法创建对象使用,需要使用底层的子类创建对象使用
4.集合的框架
集合按照其存储结构可以分为两大类,分别是单列集合java.util.java.util.
Collection:单列集合的根接口,用于存储一系列符合某种规则的元素。
Collection集合有两个重要的子接口,分别是List和Set。其中,List集合的特点是元素有序、可重复;Set集合的特点是元素无序并且不可重复。List接口的主要实现类有ArrayList 和LinkedList;Set接口的主要实现类有HashSet和TreeSet。
Map:双列集合的根接口,用于存储具有键(Key)、值(Value)映射关系的元素。
Map集合中每个元素都包含一对键值,并且Key是唯一的,在使用Map集合时可以通过指定的Key找到对应的Value。例如根据一个学生的学号就可以找到对应的学生。Map接口的主要实现类有HashMap和TreeMap。
二、Collection接口

1.Collection是所有单列集合的父接口,因此在Collection中定义了单列集合(List和Set)通用的一些方法,任意的单列集合都可以使用Collection接口中的方法。
2.共性的方法:
- public boolean add(E e): 把给定的对象添加到当前集合中 。返回值为是否添加成功。
- public boolean addAll(Collection c):将集合c中的所有元素添加到调用该方法的集合中。
- public void clear() :清空集合中所有的元素。
- public boolean remove(E e): 把给定的对象e在当前集合中删除。
- public boolean removeAll(Collection c): 删除该集合中包含集合c中的所有元素。
- public boolean contains(E e): 判断当前集合中是否包含给定的对象e。
- public boolean containsAll(Collection c):判断当前集合中是否包含集合c中的所有元素。
- public boolean isEmpty(): 判断当前集合是否为空。
- public int size(): 返回集合中元素的个数。
- public Object[] toArray(): 把集合中的元素,存储到Object类型的数组中。
- Iterator iterator():返回在该集合的元素上进行迭代的迭代器(Iterator),用于遍历该集合所有元素。
- Stream<E> stream():将集合源转换为有序元素的流对象。
import java.util.ArrayList;
import java.util.Collection;
public class CollectionTest {
public static void main(String[] args) {
//多态:创建集合对象
Collection<String> collection = new ArrayList<>();
System.out.println(collection);//[]
//add方法 添加元素
collection.add("真皮沙发");
collection.add("张三");
collection.add("李四");
collection.add("王五");
collection.add("赵六");
System.out.println(collection);//[真皮沙发, 张三, 李四, 王五, 赵六]
//remove方法 删除某个元素
collection.remove("王五");
collection.remove("田七");//删除失败返回false
System.out.println(collection);//[真皮沙发, 张三, 李四, 赵六]
//contains方法 判断是否包含某个元素
boolean b = collection.contains("李四");
System.out.println("判断李四是否在集合中:" + b);//true
//isEmpty方法 判断集合是否为空
System.out.println("判断集合是否为空:" + collection.isEmpty());//false
//size方法 获取集合中元素的个数
System.out.println("元素个数:" + collection.size());//4
//toArray方法 将集合存储到一个Object数组
Object[] array = collection.toArray();
for (int i = 0; i < array.length; i++) {
System.out.println(array[i]);//真皮沙发 张三 李四 赵六
}
//clear方法 清空集合中的元素
collection.clear();
System.out.println(collection);//[]
System.out.println("判断集合是否为空:" + collection.isEmpty());//true
}
}
tips: 有关Collection中的方法可不止上面这些,其他方法可以自行查看API学习。
第13课 Iterator迭代器、foreach循环、 forEach方法
一、Iterator接口遍历集合
在程序开发中,经常需要遍历集合中的所有元素。针对这种需求,JDK专门提供了一个接口
Iterator。java.util.Iterator接口也是Java集合中的一员,但它与Collection、Map接口有所不同,Collection接口与Map接口主要用于存储元素,而Iterator主要用于迭代访问(即遍历)Collection中的元素,因此Iterator对象也被称为迭代器。
1. 想要遍历Collection集合,那么就要获取该集合迭代器完成迭代操作,下面介绍一下获取迭代器的方法
- public Iterator<E> iterator(): 返回该集合对应的迭代器,用来遍历集合中的元素。
2.迭代的概念: Collection集合元素的通用获取方式。在取元素之前先要判断集合中有没有元素,如果有,就把这个元素取出来,继续在判断,如果还有就再取出出来,一直把集合中的所有元素全部取出。这种取出方式专业术语称为迭代。
3. Iterator接口的常用方法
- boolean hasNext():如果仍有元素可以迭代,则返回 true。判断集合中还有没有下一个元素,有就返回true,没有就返回false。
- E next():返回迭代的下一个元素。取出集合中的下一个元素(并没有删除元素)。
4.迭代器的使用步骤(重点)
- 使用集合中的方法iterator()获取迭代器的实现类对象,使用Iterator接口接收(多态)。
- 使用Iterator接口中的hasNext()方法判断还有没有下一个元素。
- 使用Iterator接口中的next()方法取出集合中的下一个元素。
注意: Iterator<E>接口也是有泛型的,迭代器的泛型跟着集合走,集合是什么泛型,迭代器就是什么泛型。
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
public class IteratorTest {
public static void main(String[] args) {
//创建一个集合
Collection<String> collection = new ArrayList<>();
//添加元素
collection.add("张三");
collection.add("李四");
collection.add("王五");
collection.add("赵六");
collection.add("田七");
//获取Iterator迭代器,属于多态,左边是接口,右边是实现类对象
Iterator<String> ite = collection.iterator();
//使用hasNext方法判断还有没有下一个元素
System.out.println("判断集合中是否有元素:"+ite.hasNext());//true
//试用next方法取出集合中的下一个元素
String s = ite.next();
System.out.println(s);//张三
//使用while循环全部取出
while (ite.hasNext()){
System.out.println(ite.next());//李四 王五 赵六 田七
}
System.out.println(ite.next());//抛异常:NoSuchElementException
}
}
5.Iterator迭代器实现原理

- 使用iterator()方法获取迭代器的实现类对象时,会把指针(索引)指向集合的-1索引,此时不指向任何元素。
- 使用next()方法时,把指针向后移动一位,并读取移动一位后指向的元素然后将该元素作为返回值返回。
二、foreach循环遍历集合
1.foreach循环也叫增强for循环,是for循环的一个特殊简化版,专门用来遍历数组和集合,所有的单列集合都可以使用foreach。它的内部原理其实是个Iterator迭代器,所以在遍历的过程中,不能对集合中的元素进行增删操作。
2.格式
for(集合/数组的数据类型 临时变量名 : Collection集合名/数组名){
//写操作代码
}
举例:用foreach遍历数组和集合
import java.util.ArrayList;
public class ForeachTest {
public static void main(String[] args) {
//使用foreach遍历数组
int[] array = new int[]{1,2,3,4,5};
for (int i:array){
System.out.println(i);//1 2 3 4 5
}
//试用foreach遍历集合
ArrayList<String> arrayList = new ArrayList<>();
arrayList.add("张三");
arrayList.add("李四");
arrayList.add("王五");
arrayList.add("赵六");
arrayList.add("田七");
for (String i:arrayList){
System.out.println(i);//张三 李四 王五 赵六 田七
}
}
}
3.foreach注意事项
(1)foreach只能用于遍历,不能在便利过程中修改和添加元素。而普通for循环可以修改和添加,因此普通for循环更加灵活。
(2)如果要在遍历过程中删除元素,可使用iterator接口自带的remove()方法,这个方法对于迭代器而言是可以预知迭代次数发生改变的。
但不要使用Collection集合的remove()的方法删除元素,迭代器会因为无法预知迭代次数的改变,抛ConcurrentModificationException异常。
三、forEach方法遍历集合
forEach(Consumer action)方法是JDK8中,Iterator 接口新增的一个default实现方法,用于遍历集合。需要结合Lambda表达式进行使用。
用法:
Collection集合名/数组名.forEach(临时变量名 -> {操作代码})
下面举一个例子来比较三种方式进行遍历,可以发现这三种方式输出结果完全相同,但是forEach方法遍历的代码最为简洁。
import java.util.ArrayList;
import java.util.Iterator;
public class ForEachMethodTest {
public static void main(String[] args) {
ArrayList<Integer> list = new ArrayList<>();
//添加元素
for (int i = 0; i < 5; i++) {
list.add(i);
}
//用Iterator迭代器遍历
Iterator<Integer> ite = list.iterator();
while(ite.hasNext()){
System.out.print(ite.next());//01234
}
//用foreach循环遍历
for(int j:list){
System.out.print(j);//01234
}
//用forEach方法结合lambda表达式遍历集合
list.forEach(k -> System.out.print(k));//01234
}
}
//输出结果
//012340123401234
第14课 泛型
一、泛型概述
1.泛型是一种未知的数据类型,当我们不知道使用什么数据类型的时候,可以使用泛型。泛型也可以看作一个变量,用来接收数据类型。
2.在前面学习Collection集合时,我们知道Collection集合是可以存放任意对象的,只要把对象存储在Collection集合后,他们都会被向上转型为Object类型。当我们在取出每一个对象,并且进行相应的操作,这时必须采用强制类型转换。例如以下代码:
public class GenericTest {
public static void main(String[] args) {
Collection coll = new ArrayList();
coll.add("张三");
coll.add("李四");
//由于集合没有做任何限定,任何类型都可以给其中存放
coll.add(5);
Iterator it = coll.iterator();
while (it.hasNext()) {
//需要打印每个字符串的长度,就要把迭代出来的对象转成String类型
//实质:多态的向下转型 本来是Object obj = "张三";
String str = (String) it.next();
System.out.println(str);
}
}
}
//输出结果:
//张三
//李四
//Exception in thread "main" java.lang.ClassCastException...
可以看到程序运行时抛出ClassCastException异常。由于Collection集合中什么类型的元素都可以存储,但是Integer类型的5并不能强制转换为String类型,因此抛出了运行时异常ClassCastException。
那么如何解决这个问题?Collection集合虽然可以存储各种对象,但实际上Collection集合通常只存储同一类型的对象,例如都是存储字符串对象。因此在JDK5之后,新增了泛型(Generic)语法,让你在设计API时可以指定类、方法或者接口所支持的泛型,并得到了编译时的语法检查,如果类型不正确将直接在编译阶段报错。
3.泛型的类型如何确定
一般在创建对象时,将未知的类型确定具体的类型。当没有指定泛型时,默认类型为Object类型。
//将数据类型String赋值给泛型E,并创建一个ArrayList ArrayList<String> list = new ArrayList<>();
二、使用泛型的好处与弊端
1. 泛型的好处
- 将运行时期的ClassCastException异常,转移到了编译时期直接报错。
- 避免了类型转换的麻烦,存储的是什么类型,取出的就是什么类型。
2. 泛型的弊端
- 泛型是什么类型,就只能存储什么类型的数据。
import java.util.*;
public class GenericAdvantageTest {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list.add("张三");
list.add("李四");
list.add("王五");
//list.add(1);//这么写会报错
//使用迭代器遍历list集合
Iterator<String> it = list.iterator();
while(it.hasNext()){
//无需强制转换
String s = it.next();
System.out.print(s);//张三李四王五
}
}
}
三、泛型的定义和使用
在集合中会大量使用到泛型,现在来完整地学习泛型知识。
泛型,用来灵活地将数据类型应用到不同的类、方法、接口当中。将数据类型作为参数进行传递。 例如API中的ArrayList集合:
class ArrayList<E>{
public boolean add(E e){ }
public E get(int index){ }
....
}
1.定义和使用含有泛型的类
格式如下
修饰符 class 类名<代表泛型的变量> { }
(1)在创建对象时确定泛型的类型
ArrayList<Integer> list = new ArrayList<>();
此时API中ArrayList集合中E的值就是Integer类型,如下
class ArrayList<Integer>{
public boolean add(Integer e){ }
public Integer get(int index){ }
...
}
注意:泛型不存在继承关系。像下面这种写法是错误的。
Collection<Object> list = new ArrayList<String>();//错误写法
(2)自定义泛型的类
创建对象时,确定泛型的类型。如下面这个例子
class MyGenericClass<TYPE>{
//TYPE在这里代表一种未知数据类型,届时传递什么就是什么类型
private TYPE name;
//getter和setter方法
public TYPE getName() {
return name;
}
public void setName(TYPE name) {
this.name = name;
}
}
public class GenericClassTest {
public static void main(String[] args) {
//不写泛型则泛型默认为Object类型
MyGenericClass myGenericClass_1 = new MyGenericClass();
myGenericClass_1.setName("不指定泛型则默认为Object类型");
Object name_1 = myGenericClass_1.getName();
System.out.println(name_1);//不指定泛型则默认为Object类型
//创建MyGenericClass对象,泛型使用Integer类型
MyGenericClass<Integer> myGenericClass_2 = new MyGenericClass<>();
myGenericClass_2.setName(123);
Integer name_2 = myGenericClass_2.getName();
System.out.println(name_2);//123
//创建MyGenericClass对象,泛型使用String类型
MyGenericClass<String> myGenericClass_3 = new MyGenericClass<>();
myGenericClass_3.setName("只能为字符串");
String name_3 = myGenericClass_3.getName();
System.out.println(name_3);//只能为字符串
}
}
2.定义和使用含有泛型的方法
格式如下:泛型定义在方法的修饰符和返回值类型之间
修饰符 <代表泛型的变量> 返回值类型 方法名(参数列表(使用泛型)){ //方法体 }
调用方法时,确定泛型的类型。如下面的例子
class MyGenericMethod{
//定义一个含有泛型的普通方法
public <TYPE> void commonMethod(TYPE name){
System.out.println(name);
}
//定义一个含有泛型的静态方法
public static <TYPE> void staticMethod(TYPE name){
System.out.println(name);
}
}
public class GenericMethodTest {
public static void main(String[] args) {
//创建一个MyGenericClass对象
MyGenericMethod myGenericMethod = new MyGenericMethod();
myGenericMethod.commonMethod(123);//123
myGenericMethod.commonMethod(123.456);//123.456
myGenericMethod.commonMethod("传递什么类型泛型就是什么类型");//传递什么类型泛型就是什么类型
myGenericMethod.commonMethod(true);//true
//静态方法,不要创建对象使用
MyGenericMethod.staticMethod("静态方法,不要创建对象使用");//静态方法,不要创建对象使用
}
}
3. 定义和使用含有泛型的接口
(1)格式如下:
修饰符 interface接口名<代表泛型的变量> { }
(2)使用方法:
- 方式一:定义实现类时就确定泛型的类型
定义接口的实现类来实现接口,并指定接口的泛型。例如Scanner类就是使用此方式重写了Iterator接口的next方法。
public interface Iterator<E> {
E next();
}
//Scanner类实现了Iterator接口,并指定接口的泛型为String,所以重写的next方法泛型默认就是String
public final class Scanner implements Iterator<String>{
public String next() {//方法体}
}
- 方式二:始终不确定泛型的类型,直到创建对象时,确定泛型的类型
这种方式接口使用什么泛型,实现类就使用什么泛型,类跟着接口走。例如ArrayList类就使用了这种方式重写了List接口的add方法和get方法。
public interface List<E>{
boolean add(E e);
E get(int index);
}
public class ArrayList<E> implements List<E>{
public boolean add(E e) {}
public E get(int index) {}
}
(3)举例: 定义和使用含有泛型的接口
//定义泛型接口
interface MyGenericInterface<TYPE>{
void show(TYPE content);
}
//方式一:定义实现类时就确定泛型的类型
class ImpMyGenericInterface_1 implements MyGenericInterface<String>{
@Override
public void show(String content) {
System.out.println(content);
}
}
//方式二:接口使用什么泛型,实现类就使用什么泛型
class ImpMyGenericInterface_2<TYPE> implements MyGenericInterface<TYPE>{
@Override
public void show(TYPE content) {
System.out.println(content);
}
}
//使用泛型接口
public class GenericInterfaceTest {
public static void main(String[] args) {
//方式一
ImpMyGenericInterface_1 obj_1 = new ImpMyGenericInterface_1();
obj_1.show("定义类时确定泛型的类型");
//方式二
ImpMyGenericInterface_2<Integer> obj_2 = new ImpMyGenericInterface_2<>();
obj_2.show(123);
}
}
//运行结果:
//定义类时确定泛型的类型
//123
四、泛型通配符
当使用泛型类或者接口时,传递的数据中,如果泛型类型不确定,则可以通过通配符<?>表示。但是一旦使用泛型的通配符后,只能使用Object类中的共性方法,集合中元素自身方法无法使用。
1.泛型通配符的基本使用
不知道使用什么类型来接收的时候,此时可以使用?,?表示任意的数据类型。 此时只能接受数据,不能往该集合中存储数据。
使用方式:只能作为方法的参数使用,不能创建对象使用。
import java.util.ArrayList;
import java.util.Iterator;
public class GenericWildcardTest {
public static void main(String[] args) {
ArrayList<Integer> list_1 = new ArrayList<>();
list_1.add(123);
list_1.add(456);
ArrayList<String> list_2 = new ArrayList<>();
list_2.add("张三李四");
list_2.add("王五赵六");
showArray(list_1);
showArray(list_2);
}
public static void showArray(ArrayList<?> list){
//使用迭代器遍历集合
Iterator<?> ite = list.iterator();
//next()方法,取出的元素是Object类型,可以接收任意的数据类型
Object o = ite.next();
System.out.println(o);
}
}
//123
//张三李四
2.泛型通配符的高级使用——受限泛型
之前设置泛型的时候,是可以任意设置的,只要是类就可以设置。但是在JAVA的泛型中可以指定一个泛型的上限和下限。
泛型的上限限定:
- 格式
类型名称 <? extends 类 > 对象名称
- 含义:此时的泛型?,只能接收该类型及其子类。
泛型的下限限定:
- 格式
类型名称 <? super 类 > 对象名称
- 含义:此时的泛型?, 只能接收该类型及其父类。
import java.util.ArrayList;
import java.util.Collection;
public class GenericWildcardAdvancedUsageTest {
public static void main(String[] args) {
Collection<Integer> list_1 = new ArrayList<>();
Collection<String> list_2 = new ArrayList<>();
Collection<Number> list_3 = new ArrayList<>();
Collection<Object> list_4 = new ArrayList<>();
getElement_1(list_1);
//getElement_1(list_2);//报错,String类不是Number类的子类
getElement_1(list_3);
//getElement_1(list_4);//报错,Object类不是Number类的子类
//getElement_2(list_1);//报错,Integer类不是Number类的父类
//getElement_2(list_2);//报错,String类不是Number类的父类
getElement_2(list_3);
getElement_2(list_4);
}
//泛型的上限:此时的泛型?,必须是Number类型或者Number类型的子类
public static void getElement_1(Collection<? extends Number> collection) {
System.out.println(collection);
}
//泛型的下限:此时的泛型?,必须是Number类型或者Number类型的父类
public static void getElement_2(Collection<? super Number> collection){
System.out.println(collection);
}
}
第15课 List接口、LinkedList集合
一、List接口
1.java.util.List接口继承自
2.List接口的特点
- 它是一个元素存取有序的集合。例如,存元素的顺序是333、666、999。那么集合中,元素的存储就是按照333、666、999的顺序完成的。
- 它是一个带有索引的集合,通过索引就可以精确的操作集合中的元素(与数组的索引是一个道理)。
- 集合中可以有重复的元素,通过元素的equals方法,来比较是否为重复的元素。
3.List接口中常用方法
(1)List集合作为Collection集合的子接口,不但继承了Collection接口中的全部方法,而且还增加了一些根据元素索引来操作集合的特有方法:
- public void add(int index, E element): 将指定的元素,添加到该集合中的指定位置上。
- public boolean addAll(int index, Collection c) :将集合c的所有元素,添加到List集合的指定位置。
- public E get(int index):返回集合中指定位置的元素。
- public E remove(int index): 移除列表中指定位置的元素,返回的是被移除的元素。
- public E set(int index, E element):用指定元素替换集合中指定位置的元素,返回被替换的元素。
注意:操作索引的时候,一定要防止索引越界异常
- IndexOutOfBoundsException: 索引越界异常,集合会报
- ArrayIndexOutOfBoundsException: 数组索引越界异常
- StringIndexOutOfBoundsException: 字符串索引越界异常
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class ListTest {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("张三");
list.add("李四");
list.add("王五");
list.add("赵六");
list.add("田七");
//输出List集合
System.out.println(list);//[张三, 李四, 王五, 赵六, 田七]
//add方法:在索引为3的位置插入法外狂魔
list.add(3, "法外狂魔");
System.out.println(list);//[张三, 李四, 王五, 法外狂魔, 赵六, 田七]
//remove方法:移除索引为5的元素
System.out.println("被移除的元素是:" + list.remove(5));//田七
System.out.println(list);//[张三, 李四, 王五, 法外狂魔, 赵六]
//set方法:替换索引为1的元素
System.out.println("被替换的元素是:" + list.set(1, "李二"));//李四
System.out.println(list);//[张三, 李二, 王五, 法外狂魔, 赵六]
//get方法:获取指定索引的元素,可以用于遍历集合
for (int i = 0; i < list.size(); i++) {
System.out.print(list.get(i) + " ");//张三 李二 王五 法外狂魔 赵六
}
//还有以下三种遍历方法不要忘了哦
Iterator<String> ite = list.iterator();
while (ite.hasNext()) {
System.out.print(ite.next() + " ");//张三 李二 王五 法外狂魔 赵六
}
for (String s : list) {
System.out.print(s + " ");//张三 李二 王五 法外狂魔 赵六
}
list.forEach(s -> System.out.print(s + " "));//张三 李二 王五 法外狂魔 赵六
}
}
(2)当然,还有一些其他常用方法

二、LinkedList集合
java.util.

1.LinkedList集合的特点
- 底层是一个链表结构:查找慢,增删快
- 集合内包含了大量操作首尾元素的方法
- 注意:使用LinkedList集合特有的方法,不能使用多态
2.LinkedList集合的常用方法
LinkedList集合可以使用List接口的所有方法,以下为LinkedList接口所特有的常用方法。
public voidpublic voidpublic voidpublic Epublic Epublic Epublic Epublic Epublic boolean
import java.util.LinkedList;
public class LinkedListTest {
public static void main(String[] args) {
LinkedList<String> linkedList = new LinkedList<>();
//添加元素
linkedList.add("张三");
linkedList.add("李四");
linkedList.add("王五");
System.out.println(linkedList);//[张三, 李四, 王五]
//addFirst方法:往链表开头添加元素
linkedList.addFirst("法外狂魔");
//addLast方法:往链表尾部添加元素。此方法等同于add方法。
linkedList.addLast("赵六");
System.out.println(linkedList);//[法外狂魔, 张三, 李四, 王五, 赵六]
//getFirst方法:返回链表第一个元素
//isEmpty方法:判断链表是否为空,为空返回true
if (!linkedList.isEmpty()) {
System.out.println(linkedList.getFirst());//法外狂魔
}
//getLast方法:返回链表中最后一个元素
System.out.println(linkedList.getLast());//赵六
//removeFirst方法:删除链表中第一个元素
System.out.println("删除的元素是:" + linkedList.removeFirst());//法外狂魔
System.out.println(linkedList);//[张三, 李四, 王五, 赵六]
//removeLast方法:删除链表中最后一个元素
System.out.println("删除的元素是:" + linkedList.removeLast());//赵六
System.out.println(linkedList);//[张三, 李四, 王五]
//pop方法:此方法等同于removeFirst方法
System.out.println("出栈的元素是:"+linkedList.pop());//张三
System.out.println(linkedList);//[李四, 王五]
//push方法:此方法等同于addFirst方法
linkedList.push("真皮沙发");
System.out.println(linkedList);//[真皮沙发, 李四, 王五]
}
}
第16课 Set接口、HashSet集合、哈希值、LinkedHashSet集合
一、Set接口介绍
1.java.util.Set接口和java.util.List接口一样,同样继承自Collection接口,它与Collection接口中的方法基本一致,并没有对Collection接口进行功能上的扩充,只是比Collection接口更加严格了。与List接口不同的是,Set接口中元素无序,并且都会以某种规则保证存入的元素不出现重复。
2.Set接口主要有两个实现类,分别是HashSet和TreeSet。 其中,HashSet是根据对象的哈希值来确定元素在集合中的存储的位置,因此具有良好的存取和查找性能。TreeSet则是以二叉树的方式来存储元素,它可以实现对集合中的元素进行排序。接下来,将对Set集合的这两个实现类进行详细讲解。
3.Set接口的特点:
- 不允许存储重复的元素
- 没有索引,没有带索引的方法,也不能使用普通的for循环遍历
4.Set集合存取元素的方式与List集合一样,本课不再赘述。
二、HashSet集合介绍
1.HashSet是Set接口的一个实现类, 它所存储的元素是不可重复的,并且元素都是无序的(即存取顺序不一致)。 HashSet底层的实现其实是一个HashMap,后面会讲。
2.HashSet是根据对象的哈希值确定元素在集合中的存储位置,因此具有良好的存取和查找性能。保证元素唯一性的方式依赖于: hashCode方法和equals方法。
当向HashSet集合中添加一个元素时,首先会调用该元素的hashCode()方法来确定元素的存储位置,然后再调用元素对象的equals()方法来确保该位置没有重复元素。
3.HashSet集合的特点:
- 不允许存储重复的元素
- 没有索引,没有带索引的方法,也不能使用普通的for循环遍历。可以采用迭代器、增强for、forEach方法遍历。
- 是一个无序的集合,存储元素和取出元素的顺序有可能不一致
- 底层是一个哈希表结构(查询的速度非常的快)
4.先看一下Set集合的存储,可以发现输出结果与存入的元素不同,可见集合中不能存储重复元素。
public class HashSetTest {
public static void main(String[] args) {
//创建 Set集合
HashSet<String> set = new HashSet<String>();
//添加元素
set.add(new String("cba"));
set.add("abc");
set.add("bac");
set.add("cba");
//遍历
for (String name : set) {
System.out.println(name);
}
}
}
//输出结果:
//cba
//abc
//bac
三、哈希值
1.哈希值是一个十进制的整数,由系统随机给出。它是对象的地址值,是一个逻辑地址,是模拟出来得到地址,不是数据实际存储的物理地址。
2.在Object类有一个int hashCode()方法,可以获取对象的哈希值。Object类的toString方法也调用了hashCode方法,只不过是用16进制表示的。
3.自定义类的哈希值
public class Demo01HashCode {
public static void main(String[] args) {
//Person类继承了Object类,所以可以使用Object类的hashCode方法
Person p1 = new Person();
int h1 = p1.hashCode();
System.out.println(h1);//1967205423(哈希值)
Person p2 = new Person();
int h2 = p2.hashCode();
System.out.println(h2);//42121758(哈希值)
/*
toString方法的源码:
return getClass().getName() + "@" + Integer.toHexString(hashCode());
*/
System.out.println(p1);//daily.may0514.Person@75412c2f
System.out.println(p2);//daily.may0514.Person@282ba1e
System.out.println(p1==p2);//false
}
}
4.String类的哈希值
String类已经重写了Obejct类的hashCode方法,只要字符串相同,则哈希值相同。
public class StringHashCodeTest {
public static void main(String[] args) {
String s1 = new String("张三李四");
String s2 = new String("王五赵六");
String s3 = new String("张三李四");
//String类重写了Obejct类的hashCode方法
//可以看到s1和s3字符串相同,哈希值也相同,
System.out.println(s1.hashCode());//745510390
System.out.println(s2.hashCode());//901662913
System.out.println(s3.hashCode());//745510390
System.out.println(s3.hashCode() == s1.hashCode());//true
//相同的字符串,哈希值相同
System.out.println("田七".hashCode());//949971
System.out.println("田七".hashCode());//949971
System.out.println("2233".hashCode());//1539232
}
}
特殊的,"重地"和"通话"的哈希值相同,应该是个bug?
四、HashSet集合存储数据的结构(哈希表)
1.哈希表
JDK8之前,哈希表底层采用数组+链表实现,即使用链表处理冲突,相同hash值的元素都存储在一个链表里。但是当位于一个桶中的元素较多,即hash值相等的元素较多时,通过key值依次查找的效率较低。
JDK8开始,哈希表存储采用数组+链表+红黑树实现,当链表长度超过阈值(8)时,将链表转换为红黑树,这样大大减少了查找时间。

.bmp)
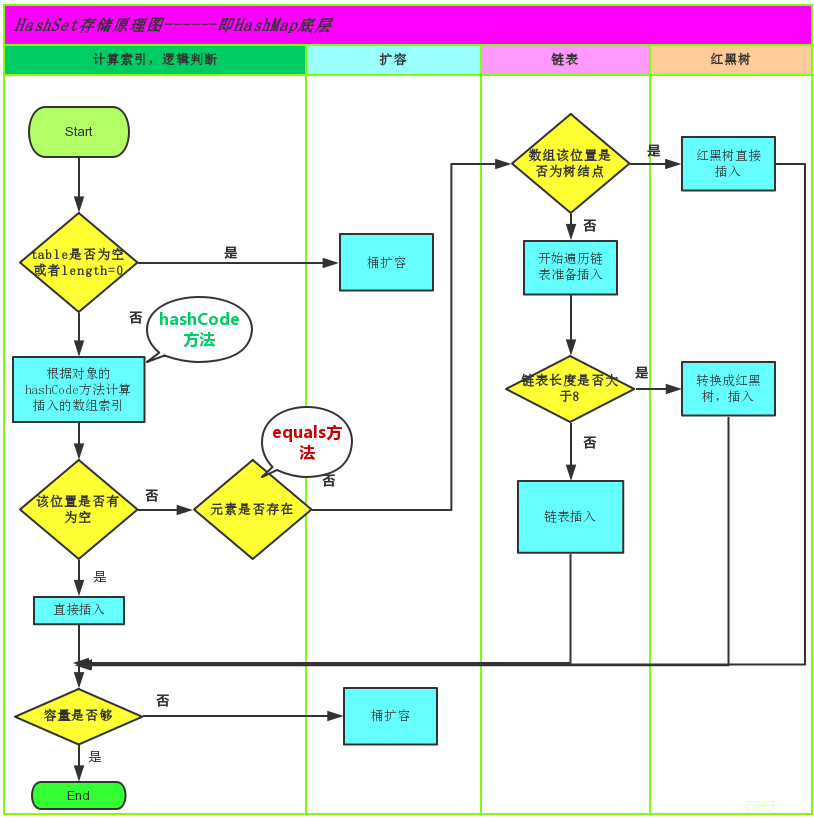
2.哈希表存储流程
当向HashSet集合中添加一个元素时,首先会调用该元素的hashCode()方法来确定元素的存储位置,然后再调用元素对象的equals()方法来确保该位置没有重复元素。
下面通过一个例子说明,你就能懂到底是咋回事了。请注意保证存储的元素不重复的前提是hashCode方法和equals方法已被重写,String类内部就已经重写了这两个方法。
import java.util.HashSet;
public class WhyHashSetNoRepeatTest {
public static void main(String[] args) {
HashSet<String> set = new HashSet<>();
String s1 = new String("abc");
String s2 = new String("abc");
//add方法会调用s1的hashCode方法,计算"abc"的哈希值是96354
//然后在集合中查找有没有哈希值是96354的元素,发现没有
//于是将s1存储在集合中
set.add(s1);
//add方法会调用s2的hashCode方法,计算"abc"的哈希值是96354
//然后在集合中查找有没有哈希值是96354的元素,发现有s1和他一样(哈希冲突)
//接下来s2调用equals方法和和哈希值相同的元素比较,s2.equals(s1),返回true
//于是不会把s2存储在集合中
set.add(s2);
//add方法会调用"重地"的hashCode方法,计算"重地"的哈希值是1179395
//然后在集合中查找有没有哈希值是1179395的元素,发现没有
//于是将"重地"存储在集合中
set.add("重地");
//add方法会调用"通话"的hashCode方法,计算"通话"的哈希值是1179395
//然后在集合中查找有没有哈希值是96354的元素,发现有"重地"和他一样(哈希冲突)
//接下来"通话"调用equals方法和和哈希值相同的元素比较,"通话".equals("重地"),返回false
//于是将"通话"存储在集合中
set.add("通话");
//同理,"abc"不会被存储
set.add("abc");
System.out.println(set);//[重地, 通话, abc]
}
}

五、HashSet集合存储自定义类型元素
1.JDK8引入红黑树大幅优化了HashMap的性能,要保证HashSet集合元素的唯一,其实就是根据对象的hashCode和equals方法来决定的。
2.如果我们往集合中存放自定义的对象,需要保证其唯一,就必须自行重写hashCode和equals方法建立属于当前对象的比较方式。
3.如下面这个例子,使用自己定义的Person类,要求同名同年龄的人,视为同一个人,只能存储一次。这就需要在Person类中重写equals方法和hashCode方法。可以使用IDEA的Alt+Insert键,一键生成。
import java.util.HashSet;
import java.util.Objects;
class Person {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
//重写equals方法
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return age == person.age &&
Objects.equals(name, person.name);
}
//重写hashCode方法
@Override
public int hashCode() {
return Objects.hash(name, age);
}
//重写toString方法,否则输出集合时打印的是地址值
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
public class HashSetSavePersonClassTest {
public static void main(String[] args) {
HashSet<Person> set = new HashSet<>();
Person p1 = new Person("张三李四",18);
Person p2 = new Person("张三李四",19);
Person p3 = new Person("王五赵六",18);
Person p4 = new Person("王五赵六",18);
System.out.println(p1.hashCode());//1635986589
System.out.println(p2.hashCode());//1635986590
System.out.println(p3.hashCode());//-2113219790
System.out.println(p4.hashCode());//-2113219790
//==比较的是地址值,不是哈希值
System.out.println(p3==p4);//false,因为p3和p4是两个对象
System.out.println(p3.equals(p4));//true
set.add(p1);
set.add(p2);
set.add(p3);
set.add(p4);
System.out.println(set);
}
}
//输出结果:
//[Person{name='王五赵六', age=18}, Person{name='张三李四', age=19}, Person{name='张三李四', age=18}]
六、LinkedHashSet集合
1.LinkedHashSet集合是HashSet集合的子类。我们知道HashSet集合保证元素唯一,可是元素存放进去是没有顺序的,如果我们要保证有序,可以使用LinkedHashSet集合。
2.LinkedHashSet集合底层是:哈希表(数组+链表/红黑树) + 链表
正是因为多了一个链表记录元素的存储顺序,保证了元素有序。
import java.util.HashSet;
import java.util.LinkedHashSet;
public class LinkedHashSetTest {
public static void main(String[] args) {
HashSet<String> set = new HashSet<>();
set.add("张三");
set.add("李四");
set.add("王五");
set.add("赵六");
set.add("田七");
//可以看到元素无序输出
System.out.println(set);//[李四, 张三, 王五, 赵六, 田七]
LinkedHashSet<String> linkedSet = new LinkedHashSet<>();
linkedSet.add("张三");
linkedSet.add("李四");
linkedSet.add("王五");
linkedSet.add("赵六");
linkedSet.add("田七");
//可以看到元素有序输出
System.out.println(linkedSet);//[张三, 李四, 王五, 赵六, 田七]
}
}
第17课 TreeSet集合、Comparable接口、 Comparator接口
一、TreeSet集合介绍
1.TreeSet是Set接口的另一个实现类,它内部采用平衡二叉树来存储元素,这样的结构可以保证TreeSet集合中没有重复的元素,并且可以对元素进行排序,始终保证元素的排列是从小到大的。
2.在TreeSet集合中,左子树上的元素小于它的根节点,右子树上的元素大于他的根节点,同一层的元素,左边的元素总是小于右边的元素。
3.存储原理
- TreeSet集合没有元素时,新增的第1个元素会在二叉树最顶层
- 接着新增元素时,首先会与根结点元素比较
- 如果小于根结点元素就与左边的分支比较
- 如果大于根结点元素就与右边的分支比较
- 如果等于根结点就不存储
- 直到最后一个元素进行比较时,如果新元素小于最后一个元素就将其放在最后一个元素的左子树上,大于则放在右子树上。

4.使用TreeSet集合存储数据时,TreeSet集合会对存入的元素进行比较排序,因此存数TreeSet集合中的元素一定要是同种数据类型。
如下面这个例子,输出TreeSet集合时数字就已经自动排好了顺序,字符串按首字母排序(不支持中文)。
import java.util.TreeSet;
public class TreeSetTest {
public static void main(String[] args) {
TreeSet<Integer> integersTreeSet = new TreeSet<>();
integersTreeSet.add(999);
integersTreeSet.add(333);
integersTreeSet.add(666);
integersTreeSet.add(111);
integersTreeSet.add(777);
System.out.println(integersTreeSet);//[111, 333, 666, 777, 999]
TreeSet<String> stringsTreeSet = new TreeSet<>();
stringsTreeSet.add("English");
stringsTreeSet.add("Dream");
stringsTreeSet.add("Brave");
stringsTreeSet.add("Active");
stringsTreeSet.add("Civilization");
stringsTreeSet.add("Green");
stringsTreeSet.add("Fashion");
System.out.println(stringsTreeSet);//[Active, Brave, Civilization, Dream, English, Fashion, Green]
}
}
5.如果没有排序需求,都应该使用性能更高的HashSet集合。
二、 TreeSet集合常用方法
TreeSet继承了Set接口的所有方法,以下仅介绍TreeSet集合的特有方法。

三、Comparable接口(自然排序)
引语:TreeSet是如何实现元素有序的
向TreeSet集合添加元素时,都会将该元素与其他元素比较,最后将其插入到有序的对象序列中。集合中的元素进行比较时,都会调用compareTo()方法,该方法是java.lang.Comparable接口中定义的,因此要想对集合中的元素进行排序,就必须实现Comparable接口。
1.为什么要使用Comparable接口
(1)Java中大部分的类都实现了Comparable接口,并默认实现了接口中唯一的方法:compareTo()方法,该方法制定的是比较规则。如Integer类、 Double类等基本类型的默认排序规则是升序排序,String类默认排序规则是按首字母升序排序。
(2)自定义类当中并没有默认实现Comparable接口的compareTo()方法,因此如果一个集合中含有用户自定义类型的数据,并且有排序的需求(如TreeSet集合),就应当考虑重写compareTo()方法。
(3)凡是本身就带有排序的功能的类(类当中有用于排序的方法),都必须实现Comparable接口。比如TreeSet集合。
2.Comparable接口介绍
(1)实现该接口的类,强行对每个实现类的对象进行整体排序。这种排序被称为类的自然排序,类的compareTo方法被称为它的自然比较方法。
(2)实现此接口的对象(和数组)可以通过Collections.sort方法和Arrays.sort方法进行自动排序,Collections工具类下一课就会介绍,Arrays工具类在第2课已经介绍过。
(3)实现此接口的对象可以用作有序映射(TreeMap集合)中的键或有序集合(TreeSet集合)中的元素,无需指定比较器。
3. compareTo方法
(1)实现了Comparable接口的类通过重写compareTo方法从而确定该类对象的排序方式。
(2)接口中通过x.compareTo(y)方法来比较x和y的大小 。其中x就相当于this指针。
该方法的返回值是int类型,返回0表示this == obj,返回正数表示this > obj,返回负数表示this < obj。
public int compareTo(Object obj);
(3)compareTo方法的重写
两个对象比较的结果有三种:大于,等于,小于。
- 如果要按照升序排序,则this < obj,返回负数;相等返回0;this > obj,返回正数。
- 如果要按照降序排序,则this < obj,返回正数;相等返回0;this > obj,返回负数。
四、Comparator接口(定制排序)
刚刚我们介绍了用于比较的接口Comparable,该接口提供了一个compareTo方法,所有实现该接口的类,都动态的实现了该方法。实际上Java还提供了一个Comparator接口,该接口也具有比较的功能。
如果说Comparable接口是自己(this)和别人(参数)比较大小,那么Comparator接口就是找一个第三方的裁判(实现该接口的类的对象),来比较两个对象的大小。
1.为什么要使用Comparator接口
(1)如果自定义类没有考虑到实现Comparable接口且该类无法被改变,或者不想按照默认的compareTo方法进行排序, 那么就需要用到另外的一个比较器接口Comparator。
例如,String类实现了Comparable接口,并重写了比较规则的定义,但是这样就把这种规则写死了,如果我想要字符串按照首字母降序排列,那么这样就要修改String类的源代码,这是不可能也不现实的,那么这个时候我们可以使用 Comparator接口。
2.Comparator接口介绍
(1)Comparator接口相当于一个比较器,作用和Comparable接口类似。实现了该接口的类或者数组可以使用Collections.sort()和Arrays.sort()来进行排序,也可以对TreeMap和TreeSet的数据结构进行精准的控制。
(2)由于我们可以自己定义一个比较器实现Comparator接口,然后重写compare方法,调用比较/排序方法时传入该自定义比较器对象,因此这种排序方法又叫定制排序。
(3)Comparator比较器必须实现的方法是compare方法,其中T为泛型,需要指定具体的数据类型
int compare(T obj1, T obj2);
自定义比较器比较器实现Comparator接口也需要指定具体类型
public class StudentComparator implements Comparator<Student>{ }
3.compare方法重写
比较器实现了Comparator接口后,必须对compare方法进行重写,来确定比较规则。与compareTo方法类似, 两个对象比较的结果同样有三种:大于,等于,小于。
- 如果要按照升序排序,则obj1 < obj2,返回负数;相等返回0;obj1 > obj2,返回正数。
- 如果要按照降序排序,则obj1 < obj2,返回正数;相等返回0;obj1 > obj2,返回负数。
五、以TreeSet集合举例以上两种排序规则
- 自然排序:向TreeSet集合中存储的元素所在类必须实现Comparable接口,并重写compareTo方法,然后TreeSet集合就会对该类型元素使用compareTo方法进行比较。
如果没有对compareTo方法进行重写,则直接抛ClassCastException异常。
import java.util.TreeSet;
class Student implements Comparable {
private String name;
private int age;
public Student(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return name + ":" + age;
}
//重写Comparable接口的compareTo方法
@Override
public int compareTo(Object o) {
//多态:向下转型
Student stu = (Student)o;
//定义比较方式,先比较age
if(this.age > stu.age){
return 1;//返回1为升序,返回-1为降序
}
//年龄相同则比较name
if(0 == this.age - stu.age){
//这里调用的是String类的compareTo方法,默认为首字母升序。
//不要与此处重写的compareTo方法混淆。
return this.name.compareTo(stu.name);
}
return -1;
}
}
public class TreeSetcompareToOverrideTest {
public static void main(String[] args) {
TreeSet<Student> treeSet = new TreeSet<>();
treeSet.add(new Student("张三",22));
treeSet.add(new Student("李四",19));
treeSet.add(new Student("王五",19));
treeSet.add(new Student("赵六",21));
treeSet.add(new Student("田七",20));
treeSet.add(new Student("田七",18));//同名不同龄
treeSet.add(new Student("赵六",21));//重复
System.out.println(treeSet);
}
}
//输出结果:
//[田七:18, 李四:19, 王五:19, 田七:20, 赵六:21, 张三:22]
- 定制排序
(1)这种排序依赖的是TreeSet构造方法,需要自己写一个实现类实现Comparator接口,并重写其中的compare(Object o1,Object o2)方法。当然,为了方便我们可以直接使用匿名内部类或Lambda表达式,省去定义实现类的操作。
(2)如下面这个例子,我们想按字符串长度进行升序
import java.util.Comparator;
import java.util.TreeSet;
class Boy {
private String name;
private int age;
public Boy(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
@Override
public String toString() {
return name + ":" + age;
}
}
//定义实现类(太麻烦,不推荐)
class MyCompareRule implements Comparator<Boy>{
@Override
public int compare(Boy o1, Boy o2) {
if (o1.getName().length() >= o2.getName().length()){
return 1;//返回1为升序,返回-1为降序
}
return -1;
}
}
public class TreeSetCustomSortTest {
public static void main(String[] args) {
//使用匿名内部类(同时也是匿名对象)
TreeSet<Boy> treeSet = new TreeSet<>(new Comparator<Boy>() {
@Override
public int compare(Boy boy1, Boy boy2) {
if (boy1.getName().length() >= boy2.getName().length()) {
return 1;//返回1为升序,返回-1为降序
}
return -1;
}
});
//使用Lambda表达式
TreeSet<Boy> treeSetByLambda = new TreeSet<>((boy1, boy2) -> {
if (boy1.getName().length() >= boy2.getName().length()) {
return 1;
}
return -1;
});
//使用实现类(太麻烦,不推荐)
TreeSet<Boy> treeSetByImp = new TreeSet<>(new MyCompareRule());
treeSet.add(new Boy("Amy", 22));
treeSet.add(new Boy("Bob", 19));
treeSet.add(new Boy("Cloud", 19));
treeSet.add(new Boy("DaMing", 21));
treeSet.add(new Boy("Eve", 20));
treeSet.add(new Boy("Franklin", 18));
treeSet.add(new Boy("Gina", 21));
System.out.println(treeSet);
}
}
//输出结果:
//[Amy:22, Bob:19, Eve:20, Gina:21, Cloud:19, DaMing:21, Franklin:18]
第18课 Collections工具类
一、Collections工具类
在Java中,针对集合的操作非常频繁,例如将集合中的元素排序、从集合中查找某个元素等。针对这些常见操作,Java提供了一个java.util.Collections工具类专门用来操作集合。
二、 Collections工具类常用方法
Collections类提供了大量的静态方法对集合中的元素进行排序、查找和修改。
1.添加、排序操作(均为静态方法)
- boolean addAll(Collection<T> c, T... elements):往集合中添加一些元素。
- void reverse(List<?> list):反转集合中的元素。
- void shuffle(List<?> list):将集合中的元素打乱顺序。
- void sort(List<T> list):将集合中元素按照默认规则排序。默认规则:数字升序,字符串按首字母升序。
- void sort(List<T> list,Comparator<? super T>):将集合中元素按照指定规则排序。
(1)以上方法在基本数据类型和String类型的应用
import java.util.ArrayList;
import java.util.Collections;
import java.util.LinkedList;
public class CollectionsAddAndSortMethodTest {
public static void main(String[] args) {
LinkedList<String> linkedlist = new LinkedList<>();
//addAll方法:添加所有指定元素到指定集合
Collections.addAll(linkedlist,"张三","李四","王五","赵六","田七");
System.out.println(linkedlist);//[张三, 李四, 王五, 赵六, 田七]
//reverse方法:反转集合中所有元素
Collections.reverse(linkedlist);
System.out.println(linkedlist);//[田七, 赵六, 王五, 李四, 张三]
//swap方法:将指定集合中两个元素互换
Collections.swap(linkedlist,0,1);
System.out.println(linkedlist);//[赵六, 田七, 王五, 李四, 张三]
//shuffle方法:打乱集合中元素顺序
Collections.shuffle(linkedlist);
System.out.println(linkedlist);//[田七, 李四, 王五, 张三, 赵六]
ArrayList<Integer> list = new ArrayList<>();
Collections.addAll(list,81,64,9,36,25,16,49,4,1);
//sort方法:排序
Collections.sort(list);
System.out.println(list);//[1, 4, 9, 16, 25, 36, 49, 64, 81]
}
}
(2) sort(List<T> list)方法对自定义类的对象进行排序,需要实现Comparable接口。
import java.util.ArrayList;
import java.util.Collections;
//自定义的学生类,如果有排序需求就要实现Comparable接口
class Student implements Comparable {
private String name;
private int age;
public Student(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return name + ":" + age;
}
//重写Comparable接口的compareTo方法
@Override
public int compareTo(Object o) {
//多态:向下转型
Student stu = (Student) o;
//定义比较方式,先比较age
if (this.age > stu.age) {
return 1;//返回1为升序,返回-1为降序
}
//年龄相同则比较name
if (0 == this.age - stu.age) {
//这里调用的是String类的compareTo方法,默认为首字母升序。
//不要与此处重写的compareTo方法混淆。
return this.name.compareTo(stu.name);
}
return -1;
}
}
public class SortTest {
public static void main(String[] args) {
ArrayList<Student> list = new ArrayList<>();
list.add(new Student("张三", 22));
list.add(new Student("李四", 19));
list.add(new Student("王五", 19));
list.add(new Student("赵六", 21));
list.add(new Student("田七", 20));
list.add(new Student("田七", 18));//同名不同龄
list.add(new Student("赵六", 21));//重复
//通过实现Comparable接口,调用sort方法升序排序
Collections.sort(list);
System.out.println(list);
}
}
//输出结果:
//[田七:18, 李四:19, 王五:19, 田七:20, 赵六:21, 张三:22]
(3)sort(List<T> list,Comparator<? super T>) 方法,需要自己写Comparator接口的实现类,并重写其中的compare方法,来自定义比较规则,进而实现自定义排序规则。
使用此方法的好处是不需要被比较的对象实现Comparable接口,或者被比较的对象默认实现了Comparable接口,你想对它默认的排序方法进行修改,这时候使用Comparator接口就比较灵活。
如下面这个例子,String类默认是按照首字母升序排序,我们想让他按照字符串长度升序或者降序排序,只需要自己写一个实现Comparator接口的比较器,然后调用sort方法即可,而不是去修改String类的源码(这一听就不现实嘛)。
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
//定义实现类(有点麻烦,不推荐)
class MyCompareRule implements Comparator<String>{
@Override
public int compare(String s1, String s2) {
if (s1.length() >= s2.length()){
return 1;//返回1为升序,返回-1为降序
}
return -1;
}
}
public class SortComparatorTest {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list,"Amy","Bob","Cloud","DaMing","Eve","Franklin","Gina");
//使用实现类对象作为参数传入sort方法(有点麻烦,不推荐),按字符串长度升序排序
Collections.sort(list,new MyCompareRule());
System.out.println(list);//[Amy, Bob, Eve, Gina, Cloud, DaMing, Franklin]
//使用匿名内部类创建一个比较器,按字符串长度降序排序
Collections.sort(list, new Comparator<String>() {
@Override
public int compare(String s1, String s2) {
if (s1.length() >= s2.length()){
return -1;//返回1为升序,返回-1为降序
}
return 1;
}
});
System.out.println(list);//[Franklin, DaMing, Cloud, Gina, Eve, Bob, Amy]
}
}
2.查找、替换操作(均为静态方法)
- int binarySearch(List list,Object key):使用二分法搜索指定对象在List集合中的索引,查找的List集合中的元索必须是有序的
- Object max(Collection col):根据元索的自然顺序,返回给定集合中最大的元素
- Object min(Collection col):根据元素的自然顺序,返回给定集合中最小的元素
- boolean replaceAll(List list,Object oldVal, Object newVal):用一个新值newVal替换List集合中所有的旧值oldVal
import java.util.ArrayList;
import java.util.Collections;
public class CollectionsSearchTest {
public static void main(String[] args) {
//创建集合并添加元素
ArrayList<Integer> list = new ArrayList<>();
Collections.addAll(list, 4, 16, 9, 1, 49, 81, 64, 25, 36, 81);
//max方法和min方法
System.out.println("集合中最大元素" + Collections.max(list));//81
System.out.println("集合中最小元素" + Collections.min(list));//1
//sort方法排序
Collections.sort(list);
System.out.println(list);//[1, 4, 9, 16, 25, 36, 49, 64, 81, 81]
//binarySearch方法查找元素
System.out.println("元素36的下标:" + Collections.binarySearch(list, 36));//5
//replaceAll方法用999替换集合中所有的81
Collections.replaceAll(list, 81, 999);
System.out.println(list);//[1, 4, 9, 16, 25, 36, 49, 64, 999, 999]
}
}
第19课 Map接口、Entry接口 、Map集合遍历
一、Map接口介绍
现实生活中,我们常会看到这样的一种集合:IP地址与主机名,身份证号与个人,系统用户名与系统用户对象等,这种一一对应的关系,就叫做映射。Java提供了专门的集合类用来存放这种对象关系的对象,即java.util.Map接口。 该集合的常用子类有HashMap集合、LinkedHashMap集合、TreeMap集合、Properties集合。
1.Map集合特点
java.util.Map<k,v>
- Map集合是一个双列集合,一个元素包含两个值(一个key,一个value)
- Map集合中的元素,key和value的数据类型可以相同,也可以不同
- Map集合中的元素,key是不允许重复的,value是可以重复的
- Map集合中的元素,key和value是一一对应,一个key对应一个value,通过key找到对应的value
2.Map集合和Collections集合的区别
- Collection接口中的集合,元素是孤立存在的(理解为单身),向集合中存储元素采用一个个元素的方式存储。
- Map接口中的集合,元素是成对存在的(理解为夫妻)。每个元素由键与值两部分组成,通过键可以找对所对应的值。
- Collection接口中的集合称为单列集合,Map接口中的集合称为双列集合。
- Map接口中的集合不能包含重复的键,值可以重复;每个键只能对应一个值。

二、Map接口常用方法
- V put(K key, V value): 把指定的键与指定的值添加到Map集合中。 存储键值对的时候,key不重复,返回值V是null;key重复,会使用新的value替换map中重复的value,返回被替换的value值 。
- V remove(Object key): 把指定的键所对应的键值对元素在Map集合中删除,返回被删除元素的值,若不存在,返回null。
- V get(Object key):根据指定的键,在Map集合中获取对应的值。
- boolean containsKey(Object key):判断集合中是否包含指定的键。
- boolean containsValue(Object value):判断集合中是否包含指定的值。
- Set<K> keySet():获取Map集合中所有的键,存储到Set集合中并返回该Set集合。
- Collection values(): 获取Map集合中所有的值,存储到Collection集合中并返回该Collection集合。
- Set<Map.Entry<K,V>> entrySet():获取Map集合中所有的键值对对象的集合(Set集合)。
- int size():返回Map集合键值对映射的个数。
JDK8新增的Map接口方法如下,其中replace方法返回值错误,应当返回被替换前的值,而不是返回true/false,书上乱写。

import java.util.*;
public class MapTest {
public static void main(String[] args) {
//创建Map集合
HashMap<String, String> hashMap1 = new HashMap<>();
//1.put(K key, V value)方法
//存储键值对的时候,key不重复,返回值V是null
//存储键值对的时候,key重复,会使用新的value替换map中重复的value,返回被替换的value值
String v1 = hashMap1.put("邓超","孙俪");
System.out.println(v1);//null
//key不变,value改变
String v2 = hashMap1.put("邓超","还是孙俪");
System.out.println(v2);//孙俪,返回的是被替换的value
System.out.println(hashMap1);//{邓超=还是孙俪},说明重写了toString方法
hashMap1.put("冷锋","龙小云");
hashMap1.put("杨过","小龙女");
hashMap1.put("YDD","XHH");
System.out.println(hashMap1);//{邓超=还是孙俪, 杨过=小龙女, YDD=XHH, 冷锋=龙小云}
//2.remove(Object key)方法,删除键值对,返回被删除的值
HashMap<String, Integer> hashMap2 = new HashMap<>();
hashMap2.put("赵丽颖",168);
hashMap2.put("杨颖",165);
hashMap2.put("mySoul",162);
Integer v3 = hashMap2.remove("杨颖");
System.out.println(v3);//165,返回被删除的value
Integer v4 =hashMap2.remove("张三李四");
System.out.println(v4);//null,找不到相应的key返回null
//3.get(Object key)方法,key存在,返回对应的value值,不存在返回null
Integer v5 = hashMap2.get("XHH");
System.out.println(v5);//162,根据key返回对应的value
//4.containsKey(Object key)方法,判断集合中是否包含指定的键(key)
boolean v6 = hashMap1.containsKey("邓超");
System.out.println(v6);//true
System.out.println(hashMap2.containsKey("冷风"));//false
//5.containsValue(Object value)方法,判断集合中是否包含指定的值(value)
System.out.println(hashMap1.containsValue("龙小云"));//true
System.out.println(hashMap1.containsValue("冷锋"));//false
//6.keySet()方法,获取Map集合中所有的键,存储到Set集合中并返回该Set集合
Set<String> set1 = hashMap1.keySet();
System.out.println(set1);//[邓超, 杨过, YDD, 冷锋]
//7.values()方法,获取Map集合中所有的值,存储到Collection集合中并返回该Collection集合
Collection<String> collection = hashMap1.values();
System.out.println(collection);//[还是孙俪, 小龙女, XHH, 龙小云]
//8.entrySet()方法:获取Map集合中所有的键值对对象的集合(Set集合)。
Set<Map.Entry<String, Integer>> set2 = hashMap2.entrySet();
System.out.println(set2);//[赵丽颖=168, mySoul=162]
//9.size()方法:返回Map集合键值对映射的个数。]
System.out.println(hashMap1.size());//4
//10.remove(Object key,Object value)方法:删除Map集合中键值映射同时匹配的元素,返回是否删除成功
System.out.println(hashMap1.remove("冷锋","小龙女"));//false
System.out.println(hashMap1.remove("冷锋","龙小云"));//true
System.out.println(hashMap1);//{邓超=还是孙俪, 杨过=小龙女, YDD=XHH}
//11.replace(Object key,Object value)方法:将map集合中指定键对象key所映射的值替换为value,返回被替换的值
System.out.println(hashMap2.replace("赵丽颖",169));//168
System.out.println(hashMap2.replace("冷风",169));//null
}
}
三、Entry接口
1.Map.Entry<K,V>:在Map接口中有一个内部接口Entry,当Map集合被创建时,就会在Map集合中创建一个Entry对象,用来记录键与值,即键值对对象。
2.作用: 遍历Map集合时,就可以从每一个键值对(Entry)对象中获取对应的键与对应的值。
3.常用方法
- 获取键和值的方法:
KV- 获取所有Entry对象的方法:
Set<Map.Entry<K,V>>
四、Map集合的遍历
Map集合不能直接使用Iterator迭代器/增强for/forEach方法进行遍历,但是转成Set集合之后就可以使用了。
1.遍历方式一:键找值的方式(keySet方法)
键找值方式:即通过元素中的键,获取键所对应的值
(1)使用方法:Set<K> keySet()返回此映射中包含的键的 Set 集合。
(2)实现步骤:
- 使用Map集合中的方法keySet(),把Map集合所有的key取出来,存储到一个Set集合中
- 遍历Set集合,获取Map集合中的每一个key
- 通过Map集合中的方法get(Object key),通过key找到value
import java.util.HashMap;
import java.util.Iterator;
import java.util.Set;
public class MapTraverseByKeySetTest {
public static void main(String[] args) {
HashMap<String, Integer> hashMap = new HashMap<>();
hashMap.put("赵丽颖", 168);
hashMap.put("杨颖", 165);
hashMap.put("林志玲", 178);
//1.使用Map集合中的方法keySet(),把Map集合所有的key取出来,存储到一个Set集合中
Set<String> set = hashMap.keySet();
//2.遍历set集合,并通过Map集合的get方法输出对应的value
//方法1:forEach方法
set.forEach(key -> System.out.println(key + "=" + hashMap.get(key)));
//方法2:增强for
for (String key : set) {
System.out.println(key + "=" + hashMap.get(key));
}
//方法3:Iterator迭代器
Iterator<String> ite = set.iterator();
while (ite.hasNext()) {
//ite.next()找下一个键,get方法获取键对应的值
String key = ite.next();
System.out.println(key + "=" + hashMap.get(key));
}
}
}
//输出结果均为:
//林志玲=178
//赵丽颖=168
//杨颖=165
2.遍历方式二: 键值对方式(entrySet方法)
键找值方式:即通过集合中每个键值对(Entry)对象,获取键值对(Entry)对象中的键与值。
(1)使用方法:Set<Map.Entry<K,V>>
(2)实现步骤:
- 使用Map集合中的方法entrySet(),把Map集合中多个Entry对象取出来,存储到一个Set集合中
- 遍历Set集合,获取每一个Entry对象
- 使用Entry对象中的方法getKey()和getValue()获取键与值
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
public class MapTraverseByEntrySetTest {
public static void main(String[] args) {
HashMap<String, Integer> map = new HashMap<>();
map.put("赵丽颖", 168);
map.put("杨颖", 165);
map.put("林志玲", 178);
//使用Map集合中的方法entrySet(),把Map集合中多个Entry对象取出来,存储到一个Set集合中
Set<Map.Entry<String, Integer>> set = map.entrySet();
//遍历Set集合,获取每一个Entry对象
//需要用到getKey()和getValue()方法
//方法1:forEach方法
set.forEach(entry -> System.out.println(entry.getKey() + "=" + entry.getValue()));
//方法2:增强for
for (Map.Entry<String, Integer> entry : set) {
System.out.println(entry.getKey() + "=" + entry.getValue());
}
//方法3:Iterator迭代器
Iterator<Map.Entry<String, Integer>> ite = set.iterator();
while(ite.hasNext()){
Map.Entry<String, Integer> entry = ite.next();
System.out.println(entry.getKey() + "=" + entry.getValue());
}
}
}
//输出结果均为:
//林志玲=178
//赵丽颖=168
//杨颖=165
第20课 HashMap集合、LinkedHashMap集合、TreeMap集合
HashMap集合是Map接口的一个实现类,它用于存储键值映射关系,该集合的键和值允许为空,但键不能重复,且集合中的元素是无序的。本课内容主要介绍HashMap集合的内部存储原理和HashMap集合存储自定义类型的键值。
一、HashMap集合特点
- HashMap集合底层是哈希表:查询的速度特别的快
- JDK1.8之前:数组+单向链表
- JDK1.8之后:数组+单向链表/红黑树(链表的长度超过8):提高查询的速度
- HashMap集合是一个无序的集合,存储元素和取出元素的顺序有可能不一致
二、HashMap集合内部结构和存储原理
1.内部结构
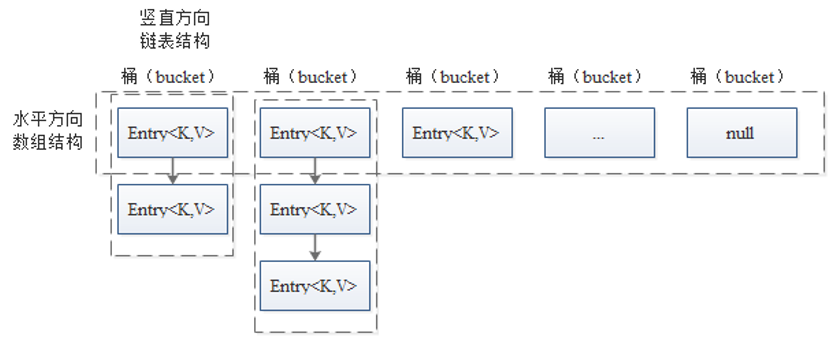
(1)在哈希表结构中,主体结构为图中水平方向的数组结构,其长度称为HashMap
集合的容量(capacity) 。
(2)数组结构垂直对应的是链表结构,链表结构称为一一个桶(bucket) ,每个桶的
位置在集合中都有对应的桶值,用于快速定位集合元素添加、查找时的位置。
2.存储原理

三、HashMap集合存储自定义类型的键值
Map集合保证key是唯一的,因此作为key的元素,必须重写hashCode方法和equals方法,以保证key唯一。
下面以String类和Person类为例,演示HashMap集合存储自定义类型的键值
import java.util.HashMap;
import java.util.Map;
import java.util.Objects;
import java.util.Set;
class Person {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
//重写equals和hashCode方法
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return age == person.age &&
Objects.equals(name, person.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
}
public class CustomizeMapTest {
public static void main(String[] args) {
//创建HashMap集合,将String类型作为键类型
//String类内部已经重写了hashCode方法和equals方法,以保证key唯一
HashMap<String,Person> map1 = new HashMap<>();
//往集合中添加元素
map1.put("北京",new Person("张三",18));
map1.put("上海",new Person("李四",19));
map1.put("广州",new Person("王五",20));
map1.put("北京",new Person("赵六",18));//这里key值重复,会将赵六替换张三
//使用keySet和增强for遍历Map集合
Set<String> set1 = map1.keySet();
for (String key : set1) {
Person value = map1.get(key);
System.out.println(key+"-->"+value);
//输出:
//上海-->Person{name='李四', age=19}
//广州-->Person{name='王五', age=20}
//北京-->Person{name='赵六', age=18}
}
//创建HashMap集合,将Person类型作为键类型
//Person类必须重写hashCode方法和equals方法,以保证key唯一
HashMap<Person,String> map2 = new HashMap<>();
//往集合中添加元素
map2.put(new Person("女王",18),"英国");
map2.put(new Person("秦始皇",18),"秦国");
map2.put(new Person("普京",30),"俄罗斯");
map2.put(new Person("女王",18),"毛里求斯");
//使用entrySet和增强for遍历Map集合
Set<Map.Entry<Person, String>> set2 = map2.entrySet();
for (Map.Entry<Person, String> entry : set2) {
Person key = entry.getKey();
String value = entry.getValue();
System.out.println(key+"-->"+value);
//输出:
//Person{name='女王', age=18}-->毛里求斯
//Person{name='秦始皇', age=18}-->秦国
//Person{name='普京', age=30}-->俄罗斯
}
}
}
四、LinkedHashMap集合
LinkedHashMap集合是HashMap集合的子类,是Map接口的哈希表和链表实现,具有可预知的迭代顺序,即元素有序排列。如果需要输出的顺序和输入顺序相同,可以使用LinkedHashMap。
底层原理:哈希表+链表(记录元素的顺序)
import java.util.HashMap;
import java.util.LinkedHashMap;
public class LinkedHashMapTest {
public static void main(String[] args) {
HashMap<String,String> map = new HashMap<>();
map.put("张三","王五");
map.put("李四","赵六");
map.put("YDD","XHH");
map.put("张三","田七");
System.out.println(map);//key不允许重复,无序输出{李四=赵六, 张三=田七, YDD=XHH}
LinkedHashMap<String,String> linked = new LinkedHashMap<>();
linked.put("张三","王五");
linked.put("李四","赵六");
linked.put("YDD","XHH");
linked.put("张三","田七");
System.out.println(linked);//key不允许重复,有序输出{张三=田七, 李四=赵六, YDD=XHH}
}
}
五、TreeMap集合
1.TreeMap是Map接口的一个实现类,它也是用来存储键值映射关系的集合,并且通过平衡二叉树的原理保证键的唯一性,这与TreeSet集合存储的原理一样,因此TreeMap中所有的键是按照某种顺序排列的。
2.默认情况下采用自然排序对键对象元素进行排序,需要保证键的类型实现Comparable接口。自然排序规则取决于Comparable接口制定的比较规则。具体参考第17课对Comparable接口的讲解。
3.和TreeSet集合一样,可以通过自定义Comparator比较器,定制比较规则,对所有的键进行定制排序,用法和TreeSet一致。具体参考第17课对Comparator接口的讲解
第21课 Stream流
在Java8中,得益于Lambda表达式所带来的函数式编程,引入了一个全新的Stream概念,用于解决已有集合类库既有的弊端。 Stream是一个接口,该接口可以将集合、数组中的元素转换为Stream流的形式,并结合Lambda表达式的优势来进一步简化集合、数组中的元素的查找、过滤、转换等操作。
一、循环遍历的弊端
1.当我们对集合进行遍历时,需要使用for循环来遍历。但我们仔细想一想可以发现:
- for循环的语法就是“怎么做”
- for循环的循环体才是“做什么”
为什么使用循环?因为要进行遍历。但循环是遍历的唯一方式吗?遍历是指每一个元素逐一进行处理,而并不是从第一个到最后一个顺次处理的循环。前者是目的,后者是方式。
2. 如果希望对集合中的元素进行筛选过滤
例如,如果一个集合中存储了学生的姓名,我们要筛选出名字为三个字的姓张的同学,那么如果用传统的循环遍历,我们要用到三次循环:
- 首先筛选所有姓张的人
- 然后筛选名字有三个字的人
- 最后进行对结果进行打印输出
import java.util.ArrayList;
import java.util.List;
public class UseForLoopTraverseTest {
public static void main(String[] args) {
//创建一个List集合,存储姓名
List<String> list = new ArrayList<>();
list.add("张无忌");
list.add("周芷若");
list.add("赵敏");
list.add("张强");
list.add("张三丰");
//对list集合中的元素进行过滤,只要以张开头的元素,存储到一个新的集合中
List<String> zhangList = new ArrayList<>();
for (String name : list) {
if (name.startsWith("张")) {
zhangList.add(name);
}
}
//对listA集合进行过滤,只要姓名长度为3的人,存储到一个新集合中
List<String> shortList = new ArrayList<>();
for (String name : zhangList) {
if (name.length() == 3) {
shortList.add(name);
}
}
//打印最终过滤后的集合
for (String name : shortList) {
System.out.println(name);
}
}
}
//输出结果:
//张无忌
//张三丰
每当我们需要对集合中的元素进行操作的时候,总是需要进行循环、循环、再循环。这是理所当然的么?不是。循环是做事情的方式,而不是目的。另一方面,使用线性循环就意味着只能遍历一次。如果希望再次遍历,只能再使用另一个循环从头开始。
那么有没有更简单直接的方式呢? Lambda的衍生物Stream流就解决了这样的问题。下面体验一下Stream流的优雅写法。
import java.util.ArrayList;
public class UseStreamTraverseTest {
public static void main(String[] args) {
//创建一个ArrayList集合,存储姓名
ArrayList<String> list = new ArrayList<>();
list.add("张无忌");
list.add("周芷若");
list.add("赵敏");
list.add("张强");
list.add("张三丰");
list.stream()//获取Stream流
.filter(s -> s.startsWith("张"))//筛选姓张的
.filter(s -> s.length() == 3)//筛选3个字的
.forEach(name -> System.out.println(name));//打印
}
}
//输出结果:
//张无忌
//张三丰
如上,直接阅读代码的字面意思即可完美展示无关逻辑方式的语义:获取流、过滤姓张、过滤长度为3、逐一打印。代码中并没有体现使用线性循环或是其他任何算法进行遍历,我们真正要做的事情内容被更好地体现在代码中。
二、Stream流的流式思想
“Stream流”其实是一个集合元素的函数模型,它并不是集合,也不是数据结构,其本身并不存储任何元素(或其地址值)。
1.整体来看,流式思想类似于工厂车间的“生产流水线”。 当需要对多个元素进行操作(特别是多步操作)的时候,考虑到性能及便利性,我们应该首先拼好一个“模型”步骤方案,然后再按照方案去执行它。如下图所示

这张图中展示了过滤、映射、跳过、计数等多步操作,这是一种集合元素的处理方案,而方案就是一种“函数模型”。图中的每一个方框都是一个“流”,调用指定的方法,可以从一个流模型转换为另一个流模型。而最右侧的数字 3是最终结果。这里的filter、map 、skip都是在对函数模型进行操作,集合元素并没有真正被处理。只有当终结方法count执行的时候,整个模型才会按照指定策略执行操作。这得益于Lambda的延迟执行特性。
2.Stream流是一个来自数据源的元素队列
- 元素是特定类型的对象,形成一个队列。 Java中的Stream并不会存储元素,而是按需计算。
- 数据源是流的来源,可以是集合、数组等。
3.与Collection操作不同, Stream操作还有两个基础的特征
- Pipelining:中间操作都会返回流对象本身。这样多个操作可以串联成一个管道, 如同流式风格(fluent style)。 这样做可以对操作进行优化,比如延迟执行(laziness)和短路( short-circuiting)。
- 内部迭代:以前对集合遍历都是通过Iterator或者增强for的方式,显式的在集合外部进行迭代,这叫做外部迭代。Stream提供了内部迭代的方式,流可以直接调用遍历方法。
4.使用Stream流的基本步骤
- 将原始集合或者数组对象转换为Stream流对象
- 对Stream流对象中的元素进行一系列的过滤、查找、排序等中间操作(Intermediate Operations),然后仍然返回一个Stream流对象
- 对Stream流进行遍历、统计、收集等终结操作( Terminal Operation),获取想要的结果,此时返回的不再是Stream流对象
- 注意:进行上述操作时,只是改变了Stream流对象中的数据,不会改变原始集合的数据。
三、创建(获取)Stream流对象
1.创建Stream流对象其实就是将集合、数组等通过一些方法转换为Stream流对象。
2.获取一个流非常简单,有以下几种常用的方式:
- 1.所有的Collection集合都可以通过stream默认方法获取Stream流对象。
- 即:default Stream stream()
- 2.Stream接口的of静态方法可以获取基本类型的包装类数组、引用类型数组和单个元素的Stream流对象。
- 即:static Stream of(T... values)
- 参数是一个可变参数,那么我们就可以传递一个数组
- 3.Arrays工具类的stream静态方法也可以获取数组元素的Stream流对象。
3.Map集合并没有提供相关方法获取Stream流对象,所以想要用Map集合创建Stream流对象必须先通过Map集合的keySet()、values()、entrySet()等方法将Map集合转换为Collection集合(或其子集合Set),然后再使用单列集合的stream()静态方法获取对应键、值集合的Stream流对象。
以下代码演示了Collection集合、Map集合、数组获取Stream流对象的方式
import java.util.*;
import java.util.stream.IntStream;
import java.util.stream.Stream;
public class GetStreamTest {
public static void main(String[] args) {
//1.获取Collection集合的Stream流对象
ArrayList<String> list = new ArrayList<>();
Stream<String> listStream = list.stream();
//2.Map集合的Stream流对象:不能直接获取,需要转换为Collection集合或其子集合
HashMap<String, String> map = new HashMap<>();
//keySet方法获取键,存储到一个Set集合中,然后获取Stream流对象
Set<String> keySet = map.keySet();
Stream<String> keyStream = keySet.stream();
//values方法获取值,存储到一个Collection集合中,然后获取Stream流对象
Collection<String> valuesCollection = map.values();
Stream<String> valueStream = valuesCollection.stream();
//entrySet方法获取键值对,存储到一个Set集合中,然后获取Stream流对象
Set<Map.Entry<String, String>> entriesSet = map.entrySet();
Stream<Map.Entry<String, String>> entryStream = entriesSet.stream();
//3.数组转换为Stream流
String[] stringsArray = new String[]{"张三","李四","王五","赵六","田七"};
int[] intArray = {333, 666, 999};
//使用Stream接口的of方法获取Stream流对象
Stream<String> stringStream1 = Stream.of(stringsArray);
Stream<int[]> intStream1 = Stream.of(intArray);
//使用Arrays工具类的stream方法获取Stream流对象
Stream<String> stringStream2 = Arrays.stream(stringsArray);
IntStream intStream2 = Arrays.stream(intArray);
}
}
四、Stream流的常用方法
Java8为Stream流对象提供了多种方法,这些方法可以被分为延迟方法和终结方法。
- 延迟方法:返回值类型仍然是Stream接口自身类型的方法,因此支持链式调用。(除了终结方法外,其余方法均为延迟方法。)
- 终结方法:返回值类型不再是Stream接口自身类型的方法,终结方法会终结当前模型,因此不再支持类似StringBuilder那样的链式调用。
1.遍历 —— forEach方法
void forEach(Consumer<? super T> action)
(1)此方法位于Stream接口中,用来遍历流中的数据,不保证元素的遍历在流中是有序执行的,它是一个终结方法,遍历之后就不能继续调用Stream流中的其他方法。
(2)此方法接收一个Consumer函数式接口参数作为遍历动作,可以是一个Lambda表达式或者方法引用。
import java.util.stream.Stream;
public class StreamMethodTest {
public static void main(String[] args) {
String[] stringsArray = new String[]{"张三", "李四", "王五", "赵六", "田七"};
Stream<String> stringStream = Stream.of(stringsArray);
//forEach方法遍历
stringStream.forEach(s -> System.out.print(s + " "));//张三 李四 王五 赵六 田七
}
}
2.过滤——filter方法
Stream<T> filter(Predicate<? super T> predicate)
此方法接收一个Predicate函数式接口参数作为筛选条件,可以是一个Lambda表达式或者方法引用。
例如我们要筛选3个字的,姓张的
import java.util.stream.Stream;
public class StreamFilterTest {
public static void main(String[] args) {
String[] stringsArray = new String[]{"张三", "张三丰", "赵敏", "周芷若", "张无忌"};
Stream<String> stringsStream = Stream.of(stringsArray);
//筛选姓张的,三个字的
stringsStream.filter(name -> name.startsWith("张"))
.filter(name -> 3 == name.length())
.forEach(s -> System.out.print(s + " "));//张三丰 张无忌
//上述操作也可以通过逻辑运算符&&完成
// stringsStream.filter(name -> name.startsWith("张") && 3 == name.length())
// .forEach(s -> System.out.print(s + " "));//张三丰 张无忌
}
}
3.映射——map方法
Stream<R> map(Function<? super T, ? extends R> mapper)
(1)该方法用于类型转换,如果需要将流中的元素映射到另一个流中,可以使用map方法。例如,将String类型转换为Integer类型,将String类型字符串转换为大写,就可以使用此方法。
(2)该接口需要一个Function函数式接口参数,可以将当前流中的T类型数据转换为另一种R类型的流。
import java.util.stream.Stream;
public class StreamMapTest {
public static void main(String[] args) {
//获取一个String类型的Stream流
Stream<String> stringStream = Stream.of("333", "666", "999", "11111");
//使用map方法,把字符串类型的整数,转换(映射)为Integer类型的整数
stringStream.map(s -> Integer.parseInt(s))//此处省略了return关键字
.forEach(s -> System.out.print(s + 100 + " "));//433 766 1099 11211
}
}
4.统计个数——count方法
long count()
此方法用于统计Stream流中元素的个数,它是一个终结方法,返回值是一个long类型的整数,所以不能再继续调用Stream流中的其他方法了。
import java.util.ArrayList;
import java.util.Collections;
import java.util.stream.Stream;
public class StreamCountTest {
public static void main(String[] args) {
ArrayList<Integer> list = new ArrayList<>();
Collections.addAll(list,1,3,5,7,2,4,6);
Stream<Integer> stream = list.stream();
System.out.println(stream.count());//7
System.out.println(list.size());//7
}
}
5.跳过——skip方法、截取——limit方法
(1)Stream<T> skip(long n)
此方法用于跳过元素,如果希望跳过前几个元素,可以使用skip方法获取一个截取之后的新流。参数为long型,如果流的当前长度大于n,则跳过前n个;否则将会得到一个长度为0的空流。
(2)Stream<T> limit(long maxSize)
此方法用于截取流中的元素,参数是一个long型, 只取用前n个,如果集合当前长度大于参数则进行截取,否则不进行操作。
以上两个方法通常组合使用,因为我们通常不是从第一个元素开始截取。
import java.util.stream.Stream;
public class StreamSkipLimitTest {
public static void main(String[] args) {
String[] stringsArray = {"喜羊羊", "沸羊羊", "美羊羊", "懒羊羊", "暖羊羊", "灰太狼", "小灰灰"};
Stream<String> stringStream = Stream.of(stringsArray);
stringStream.skip(3)//跳过前三个元素
.limit(3)//取前三个元素
.forEach(s -> System.out.print(s + " "));//懒羊羊 暖羊羊 灰太狼
}
}
6.组合——concat方法
static<T> Stream<T> concat(Stream<? extends T> a, Stream<? extends T> b)
此方法用于把流组合到一起,如果有两个流,希望合并成为一个流,那么可以使用Stream接口的静态方法concat。
import java.util.stream.Stream;
public class StreamConcatTest {
public static void main(String[] args) {
String[] Array1 = {"喜羊羊", "沸羊羊", "美羊羊", "懒羊羊", "暖羊羊", "灰太狼", "小灰灰"};
String[] Array2 = new String[]{"张三", "李四", "王五", "赵六", "田七"};
Stream<String> stream1 = Stream.of(Array1);
Stream<String> stream2 = Stream.of(Array2);
//组合两个流
Stream<String> concatStream = Stream.concat(stream1, stream2);
concatStream.forEach(s -> System.out.print(s + " "));
}
}
7.收集——collect方法
<R,A>R collect(Collector<? super T, A, R>collector)
(1)此方法用于将Stream中的元素保存为另外一种形式,如集合、字符串等。当我们需要对Stream流对象进行保存时,可使用此方法,它是一个终结方法。
(2)collect()方法使用Collector接口作为参数,Collector包含四种不同的操作:supplier(初始构造器)、accumulator(累加器)、combiner(组合器)、finisher(终结者)。这些操作听起来很复杂,但是JDK 8通过java.util.stream包下的Collectors工具类内置了各种复杂的收集操作,因此对于大部分操作来说,不需要开发者自己去实现Collectors类中的方法。
(3)Collectors工具类
Collectors是一个工具类,是JDK 8预实现Collector的工具类,它内部提供了多种Collector,我们可以直接拿来使用,非常方便。 该类有以下常用静态方法
- toCollection(): 将流中的元素全部放置到一个集合中返回,这里使用Collection,泛指多种集合。
- toList(): 将流中的元素放置到一个列表集合中去。这个列表默认为ArrayList。
- toSet(): 将流中的元素放置到一个无序集set中去。默认为HashSet。
- joining(无参或有参): joining的目的是将流中的元素全部以字符序列的方式连接到一起,空参数时无连接符,有参数时可以指定连接符,例如"-","+"等。
- collectingAndThen(归纳操作,Lambda表达式): 该方法是在归纳动作结束之后,对归纳的结果通过Lambda表达式再处理。
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class StreamCollectTest {
public static void main(String[] args) {
Integer[] array = {1, 3, 5, 7, 2, 4, 6};
Stream<Integer> stream = Stream.of(array);
//先排序,再将元素放到List集合
List<Integer> list = stream.sorted()
.collect(Collectors.toList());
System.out.println(list);//[1, 2, 3, 4, 5, 6, 7]
}
}
第22课 File类、FileFilter接口
java.io.File类是文件和目录路径名的抽象表示,主要用于文件和目录的创建、查找和删除等操作。
一、File类
1.Java把电脑中的文件和文件夹(目录)封装为了一个File类,我们可以使用File类对文件和文件夹进行操作。
2.我们可以使用File类的方法进行:
- 创建一个文件/文件夹
- 删除文件/文件夹
- 获取文件/文件夹
- 判断文件/文件夹是否存在
- 对文件夹进行遍历
- 获取文件的大小
3.File类是一个与系统无关的类,任何的操作系统都可以使用这个类中的方法。
4.要掌握File类,重点记住这3个单词
- file:文件
- directory:文件夹/目录
- path:路径
二、文件分隔符
文件分隔符分为路径分隔符和文件名称分隔符。在Win7系统配置环境变量时,不同的目录要用分号(;)隔开,写文件路径时,不同的文件夹用反斜杠(\)隔开,这样的符号,就是文件分隔符。
1.文件分隔符的静态成员变量
- static String pathSeparator:与系统有关的路径分隔符,为了方便,它被表示为一个字符串。
static char pathSeparatorChar:与系统有关的路径分隔符。 - static String separator:与系统有关的默认名称分隔符,为了方便,它被表示为一个字符串。
- static char separatorChar:与系统有关的默认名称分隔符。
2.不同的操作系统有不同的分隔符
操作路径:路径不能写死了,因为我们在Windows系统上写的代码很可能要在Linux服务器上运行,但他们的文件分隔符并不相同。
C:\develop\a\a.txt Windows系统
C:/develop/a/a.txt Linux系统
应当写成
"C:"+File.separator+"develop"+File.separator+"a"+File.separator+"a.txt"
3.获取路径分隔符和文件名称分隔符
String pathSeparator = File.pathSeparator; System.out.println(pathSeparator);//路径分隔符 Windows:分号; Linux:冒号: String separator = File.separator; System.out.println(separator);// 文件名称分隔符 Windows:反斜杠\ Linux:正斜杠/
三、File类的构造方法
File类已经重写了toString方法。
1.public
- pathname:字符串的路径名称
- 路径可以是以文件结尾,也可以是以文件夹结尾
- 路径可以是相对路径,也可以是绝对路径
- 路径可以是存在,也可以是不存在
- 创建File对象,只是把字符串路径封装为File对象,不考虑路径的真假情况
File file01 = new File("D:\\Development\\Developer\\");
System.out.println(file01);//D:\Development\Developer
2.public
- String parent:父路径
- String child:子路径
- 优点:
- 父路径和子路径,可以单独书写,使用起来非常灵活。
- 父路径和子路径都可以变化。
private static void show02() {
File file02 = new File("D:\\Development\\", "Eclipse");
System.out.println(file02);//D:\Development\Eclipse
}
3.public
- File parent:父路径
String child:子路径 - 优点:
- 父路径和子路径,可以单独书写,使用起来非常灵活。
- 父路径和子路径都可以变化。
- 父路径是File类型,可以使用File的方法对路径进行一些操作,再使用路径创建对象。
private static void show03() {
File parentFile = new File("D:\\Development\\");
File file03 = new File(parentFile,"MySQL");//此处的parentFile可以调用File类的方法
System.out.println(file03);//D:\Development\MySQL
}
四、File类的常用方法
1.获取功能的方法
- public String getAbsolutePath():返回此File对象的绝对路径名字符串,无论调用该方法File对象是绝对路径还是相对路径,都返回绝对路径的字符串。
- public String getPath():将此File对象转换为路径名字符串,调用该方法的对象是什么路径就返回什么路径的字符串。
- public String getName() :返回由此File对象表示的文件或目录的名称(由构造方法传递的路径的结尾部分)。
- public long length():返回由此File对象表示的文件的大小(单位:字节),文件不存在时返回0。此方法不能获取文件夹的大小,因为文件夹是没有大小概念的。
import java.io.File;
public class FileMethod_Get {
public static void main(String[] args) {
File file = new File("D:\\Development\\eclipse\\eclipse.exe");
System.out.println("文件名:"+file.getName());
System.out.println("文件路径:"+file.getAbsolutePath());
System.out.println("路径名:"+file.getPath());
System.out.println("文件大小:"+file.length()+"字节");
}
}
//输出结果:
//文件名:eclipse.exe
//文件路径:D:\Development\eclipse\eclipse.exe
//路径名:D:\Development\eclipse\eclipse.exe
//文件大小:425984字节
2.判断功能的方法
- public boolean exists():此File表示的文件或目录是否实际存在,存在返回true。
- public boolean isDirectory():此File表示的是否为目录,用于判断构造方法中给定的路径是否以文件夹结尾。若路径不存在返回false。
- public boolean isFile():此File表示的是否为文件,用于判断构造方法中给定的路径是否以文件结尾。若路径不存在返回false。
使用 isDirectory() 和 isFile() 方法时,通常先判断文件或目录是否存在。
import java.io.File;
public class FileMethod_Judgment {
public static void main(String[] args) {
//exists()方法
File file01 = new File("D:\\Development\\eclipse\\eclipse.exe");
System.out.println(file01.exists());//true
File file02 = new File("D:\\Development\\eclipse\\idea.exe");
System.out.println(file02.exists());//false
//isDirectory()、isFile()方法
if(file01.exists()){
System.out.println(file01.isDirectory());//false
System.out.println(file01.isFile());//true
}
if(file02.exists()){
System.out.println(file01.isDirectory());//无输出
System.out.println(file01.isFile());//无输出
}
}
}
3.创建删除功能的方法
- public boolean createNewFile():当且仅当具有该名称的文件尚不存在时,创建一个新的空文件。创建文件的路径和名称在构造方法中给出(构造方法的参数)。创建成功返回true。
- 注意事项:
- 1.此方法只能创建文件,不能创建文件夹
- 2.创建文件的路径必须存在,否则会抛出IOException异常,该异常必须处理
- public boolean mkdir():创建由此File表示的目录,只能创建单级文件夹。
- public boolean mkdirs():创建由此File表示的目录,包括任何必需但不存在的父目录,既可以创建单级文件夹,也可以创建多级文件夹。
- 注意事项:
- 1.创建文件夹的路径和名称在构造方法中给出(构造方法的参数)
- 2.此方法只能创建文件夹,不能创建文件
- 3.文件夹不存在,才创建文件夹,返回true
- 4.文件夹存在,不会创建,返回false;构造方法中给出的路径不存在返回false
- public boolean delete():删除由此File表示的文件或目录,删除成功返回true。
- 此方法可以删除构造方法路径中给出的文件/文件夹。
- 注意事项:
- 1.文件夹中有内容,不会删除,返回false;构造方法中路径不存在返回false。
- 2.delete方法是直接在硬盘删除文件/文件夹,不走回收站,删除要谨慎。
import java.io.File;
import java.io.IOException;
public class FileMethod_CreateAndDelete {
public static void main(String[] args) throws IOException {
//创建文件
File file01 = new File("D:\\Development\\newFile");
System.out.println("是否存在:"+file01.exists());//false
System.out.println("是否创建:"+file01.createNewFile());//true
System.out.println("是否存在:"+file01.exists());//true
//创建单级目录
File file02 = new File("D:\\Development\\newDir");
System.out.println("是否存在:"+file02.exists());//false
System.out.println("是否创建:"+file02.mkdir());//true
System.out.println("是否存在:"+file02.exists());//true
//创建多级目录
File file03 = new File("D:\\Development\\newDir\\newDir2");
System.out.println("是否存在:"+file03.exists());//false
System.out.println("是否创建:"+file03.mkdirs());//true
System.out.println("是否存在:"+file03.exists());//true
//删除文件
System.out.println("是否存在:"+file01.exists());//true
System.out.println("是否删除:"+file01.delete());//true
System.out.println("是否存在:"+file01.exists());//false
//删除目录
System.out.println("是否存在:"+file02.exists());//true
System.out.println("是否删除:"+file02.delete());//false,文件夹中有内容,删除失败
System.out.println("是否存在:"+file02.exists());//true
System.out.println("是否存在:"+file03.exists());//true
System.out.println("是否删除:"+file03.delete());//true
System.out.println("是否存在:"+file03.exists());//false
System.out.println("是否存在:"+file02.exists());//true
System.out.println("是否删除:"+file02.delete());//true
System.out.println("是否存在:"+file02.exists());//false
}
}
五、单个目录的遍历
- public String[] list():返回一个String数组,表示该File目录中的所有子文件或目录。遍历构造方法中给出的目录,会获取目录中所有文件/文件夹的名称,把获取到的多个名称存储到一个String类型的数组中。
- public File[] listFiles():返回一个File数组,表示该File目录中的所有的子文件或目录。遍历构造方法中给出的目录,会获取目录中所有的文件/文件夹,把文件/文件夹封装为File对象,多个File对象存储到File类型的数组中。
- 注意事项:
- 1.list方法和listFiles方法遍历的是构造方法中给出的目录
- 2.如果构造方法中给出的目录的路径不存在,会抛出空指针异常
- 3.如果构造方法中给出的路径是一个文件,也会抛出空指针异常
- 4.隐藏的文件/目录也会存储在数组当中
import java.io.File;
public class FileMethod_TraverseDir {
public static void main(String[] args) {
File file01 = new File("D:\\Development");
// list()方法
String[] fileList01 = file01.list();
for(String fileName : fileList01){
System.out.println(fileName);
}
// 输出结果:
// Developer
// eclipse
// IntelliJ IDEA
// java-1.8.0-openjdk-1.8.0.252-2.b09.redhat.windows.x86_64.zip
// LLVM
// Microsoft VS Code
// MySQL
// openjdk-1.8.0.252-2.b09.redhat.windows.x86_64
// listFiles()方法
File[] fileList02 = file01.listFiles();
for (File file:fileList02){
System.out.println(file);
}
// 输出结果:
// D:\Development\Developer
// D:\Development\eclipse
// D:\Development\IntelliJ IDEA
// D:\Development\java-1.8.0-openjdk-1.8.0.252-2.b09.redhat.windows.x86_64.zip
// D:\Development\LLVM
// D:\Development\Microsoft VS Code
// D:\Development\MySQL
// D:\Development\openjdk-1.8.0.252-2.b09.redhat.windows.x86_64
}
}
六、通过递归遍历多级目录
以下代码将打印File对象的目录中的所有子目录,以及子目录中的所有文件,用到了递归的思想。
import java.io.File;
public class Exercise_TraverseMoreDir {
public static void main(String[] args) {
//遍历file01对象的目录中的所有内容,包含子目录
File file01 = new File("D:\\Download\\Windows\\Theme");
printAllFiles(file01);
}
private static void printAllFiles(File file) {
File[] filesList = file.listFiles();
//遍历filesList
for (File f : filesList){
System.out.println(f);
//如果此时遍历到的f是目录,则递归调用printAllFiles方法,遍历f的子目录
if(f.isDirectory()){
printAllFiles(f);
}
}
}
}
七、综合练习:查找目录下所有以.png结尾的文件
以下代码将打印File对象的目录以及所有子目录中以".png"结尾的文件,同样用到递归的思想。
import java.io.File;
public class Exercise_SearchFile {
public static void main(String[] args) {
File file01 = new File("D:\\Download\\Windows\\Theme");
printSpecificName(file01);
}
private static void printSpecificName(File file) {
File[] filesList = file.listFiles();
//遍历filesList
for (File f : filesList) {
//如果遍历到的f是目录,则通过递归遍历其子目录
if (f.isDirectory()) {
printSpecificName(f);
} else {
//获取文件名并转换为小写
String fileName = f.getName().toLowerCase();
//如果文件名以.png结尾则打印出来
if (true == fileName.endsWith(".png")) {
System.out.println(f);
}
}
}
}
}
//输出结果:
//D:\Download\Windows\Theme\ASUS & In\logo.png
//D:\Download\Windows\Theme\高考\01梦想.png
//D:\Download\Windows\Theme\高考\09习惯.png
//D:\Download\Windows\Theme\高考\I-can-do-it.png
//D:\Download\Windows\Theme\高考\为梦想不止不休.png
//D:\Download\Windows\Theme\高考\几回搏.png
//D:\Download\Windows\Theme\高考\孤独坚持.png
//D:\Download\Windows\Theme\高考\必胜.png
//D:\Download\Windows\Theme\高考\相信.png
//D:\Download\Windows\Theme\高考\胜利.png
//D:\Download\Windows\Theme\高考\认真.png
//D:\Download\Windows\Theme\高考\路.png
八、FileFilter接口
1.文件过滤器
在File类中有两个和listFiles重载的方法,方法的参数传递的就是过滤器。
File[] listFiles(FileFilter filter)
(1)java.io.
作用:用来过滤文件(File对象)
抽象方法:用来过滤文件的方法
boolean accept(File pathname):测试指定抽象路径名是否应该包含在某个路径名列表中。
参数: File pathname:使用listFiles方法遍历目录,得到的每一个File对象。
(2)java.io. FilenameFilter接口:实现此接口的类实例可用于过滤文件名。
作用:用于过滤文件名称
抽象方法:用来过滤文件的方法
boolean accept(File dir, String name):测试指定文件是否应该包含在某一文件列表中。
参数:
- File dir:构造方法中传递的被遍历的目录
- String name:使用listFiles方法遍历目录,获取的每一个文件/文件夹的名称
(3)注意:两个过滤器接口是没有实现类的,需要我们自己写实现类,重写过滤的方法accept,在方法中自己定义过滤的规则。
2. FileFilter接口的原理
(1)调用listFiles方法时,listFiles方法会对构造方法中传递的目录进行遍历,获取目录中的每一个文件/文件夹,然后封装为File对象。然后将每一个对象,作为accept方法的参数,传递给accept方法,根据accept方法的返回值true/false,决定要不要将该File对象存放到File数组中。
(2)因此过滤的规则,是在accept方法中设定,只要最终返回true,则收集,返回false,则舍弃。
(3)所以,如果要查找目录下所有以.png结尾的文件,可以将代码优化如下。
import java.io.File;
import java.io.FileFilter;
public class FileFilterTest {
public static void main(String[] args) {
File file = new File("D:\\Download\\Windows\\Theme");
printSpecificName(file);
}
private static void printSpecificName(File dir) {
//创建FileFilter的实现类对象(匿名内部类)
FileFilter filter = new FileFilter() {
@Override
public boolean accept(File pathname) {
//传递的对象是一个目录则返回true继续遍历,是一个.png的文件也返回true
return pathname.isDirectory() || pathname.getName().toLowerCase().endsWith(".png");
}
};
File[] filesList = dir.listFiles(filter);
//Lambda简化
//File[] filesList = dir.listFiles(pathname -> pathname.isDirectory() || pathname.getName().toLowerCase().endsWith(".png"));
//遍历filesList
for (File f : filesList) {
//如果此时遍历到的f是目录,则递归调用printSpecificName方法,遍历子目录
if (f.isDirectory()) {
printSpecificName(f);
} else {
System.out.println(f);//遍历到的是文件则打印出来
}
}
}
}
第23课 IO、字节流、打印流
一、I/O概述
java.io包下的内容,进行输入、输出操作。输入也叫做读取数据,输出也叫做作写出
根据数据的流向分为:输入流和输出流。
-
输入流 :把数据从
其他设备上读取到内存中的流。 -
输出流 :把数据从
内存中写出到其他设备上的流。
格局数据的类型分为:字节流和字符流。
-
字节流 :以字节为单位,读写数据的流。
-
字符流
顶级父类
| 字节输入流 InputStream | 字节输出流 OutputStream | |
| 字符流 | 字符输入流 Reader | 字符输出流 |
2.1 一切皆为字节
一切文件数据(文本、图片、视频等)在存储时,都是以二进制数字的形式保存,都一个一个的字节,那么传输时一样如此。所以,字节流可以传输任意文件数据。在操作流的时候,我们要时刻明确,无论使用什么样的流对象,底层传输的始终为二进制数据。
2.2 字节输出流【OutputStream】
java.io.OutputStream抽象类是表示字节输出流的所有类的超类,将指定的字节信息写出到目的地。它定义了字节输出流的基本共性功能方法。
-
public void close():关闭此输出流并释放与此流相关联的任何系统资源。 -
public void flush():刷新此输出流并强制任何缓冲的输出字节被写出。 -
public void write(byte[] b):将 b.length字节从指定的字节数组写入此输出流。 -
public void write(byte[] b, int off, int len):从指定的字节数组写入 len字节,从偏移量 off开始输出到此输出流。 -
public abstract void write(int b):将指定的字节输出流。
小贴士:
close方法,当完成流的操作时,必须调用此方法,释放系统资源。
2.3 FileOutputStream类
OutputStream有很多子类,我们从最简单的一个子类开始。
java.io.FileOutputStream类是文件输出流,用于将数据写出到文件。
(1)构造方法
-
public FileOutputStream(File file):创建文件输出流以写入由指定的 File对象表示的文件。 -
public FileOutputStream(String name): 创建文件输出流以指定的名称(路径)写入文件。 -
当你创建一个流对象时,必须传入一个文件路径。该路径下,如果没有这个文件,会创建该文件。如果有这个文件,会清空这个文件的数据。
构造方法的作用:
1.创建一个FileOutputStream对象
2.会根据构造方法中传递的文件/文件路径,创建一个空的文件
3.会把FileOutputStream对象指向创建好的文件
-
构造举例,代码如下:
public class FileOutputStreamConstructor throws IOException {
public static void main(String[] args) {
// 使用File对象创建流对象
File file = new File("a.txt");
FileOutputStream fos = new FileOutputStream(file);
// 使用文件名称创建流对象
FileOutputStream fos = new FileOutputStream("b.txt");
}
}
(2)写出字节数据
写入数据的原理(内存-->硬盘)
java程序要向文件写入数据-->找JVM(java虚拟机)-->找OS(操作系统)-->OS调用写数据的方法-->把数据写入到文件中
字节输出流的使用步骤(重点):
1.创建一个FileOutputStream对象,构造方法中传递写入数据的目的地
2.调用FileOutputStream对象中的方法write,把数据写入到文件中
3.释放资源(流使用会占用一定的内存,使用完毕要把内存清空,提供程序的效率)
-
写出字节:
write(int b)方法,每次可以写出一个字节数据,代码使用演示:
public class FOSWrite {
public static void main(String[] args) throws IOException {
// 使用文件名称创建流对象
FileOutputStream fos = new FileOutputStream("fos.txt");
// 写出数据
fos.write(97); // 写出第1个字节
fos.write(98); // 写出第2个字节
fos.write(99); // 写出第3个字节
// 关闭资源
fos.close();
}
}
输出结果:abc
-
虽然参数为int类型四个字节,但是只会保留一个字节的信息写出。
-
:write(byte[] b)
public class FOSWrite {
public static void main(String[] args) throws IOException {
// 使用文件名称创建流对象
FileOutputStream fos = new FileOutputStream("fos.txt");
// 字符串转换为字节数组
byte[] b = "abcde".getBytes();
// 写出从索引2开始,2个字节。索引2是c,两个字节,也就是cd。
fos.write(b,2,2);
// 关闭资源
fos.close();
}
}
输出结果:cd
(3)
经过以上的演示,每次程序运行,创建输出流对象,都会清空目标文件中的数据。如何保留目标文件中数据,还能继续添加新数据呢?
-
public FileOutputStream(File file, boolean append) -
public FileOutputStream(String name, boolean append): 创建文件输出流以指定的名称写入文件。
参数:
String name,File file:写入数据的目的地
boolean append:追加写开关
- true:创建对象不会覆盖源文件,继续在文件的末尾追加写数据
- false:创建一个新文件,覆盖源文件
这两个构造方法,参数中都需要传入一个boolean类型的值,true 表示追加数据,false 表示清空原有数据。这样创建的输出流对象,就可以指定是否追加续写了,代码使用演示:
public class FOSWrite {
public static void main(String[] args) throws IOException {
// 使用文件名称创建流对象
FileOutputStream fos = new FileOutputStream("fos.txt",true);
// 字符串转换为字节数组
byte[] b = "abcde".getBytes();
// 写出从索引2开始,2个字节。索引2是c,两个字节,也就是cd。
fos.write(b);
// 关闭资源
fos.close();
}
}
文件操作前:cd
文件操作后:cdabcde
(4)
Windows系统里,换行符号是\r\n 。
代码使用演示:
public class FOSWrite {
public static void main(String[] args) throws IOException {
// 使用文件名称创建流对象
FileOutputStream fos = new FileOutputStream("fos.txt");
// 定义字节数组
byte[] words = {97,98,99,100,101};
// 遍历数组
for (int i = 0; i < words.length; i++) {
// 写出一个字节
fos.write(words[i]);
// 写出一个换行, 换行符号转成数组写出
fos.write("\r\n".getBytes());
}
// 关闭资源
fos.close();
}
}
输出结果:
a
b
c
d
e
-
\r和换行符\n:-
回车符:回到一行的开头(return)。
-
换行符:下一行(newline)。
-
-
系统中的换行:
-
Windows系统里,每行结尾是
回车+换行,即\r\n; -
Unix系统里,每行结尾只有
换行,即\n; -
Mac系统里,每行结尾是
回车,即\r
-
java.io.InputStream抽象类是表示字节输入流的所有类的超类,可以读取字节信息到内存中。它定义了字节输入流的基本共性功能方法。
-
public void close():关闭此输入流并释放与此流相关联的任何系统资源。 -
public abstract int read(): 从输入流读取数据的下一个字节。 -
public int read(byte[] b): 从输入流中读取一些字节数,并将它们存储到字节数组 b中 。
小贴士:close方法,当完成流的操作时,必须调用此方法,释放系统资源。
FileInputStream extends InputStream
FileInputStream类:文件字节输入流
作用:把硬盘文件中的数据,读取到内存中使用
构造方法:
-
: 通过打开与实际文件的连接来创建一个 FileInputStream ,该文件由文件系统中的 File对象 file命名。
-
FileInputStream(String name)
参数:读取文件的数据源
String name:文件的路径
File file:文件
构造方法的作用:
1.会创建一个FileInputStream对象
2.会把FileInputStream对象指定构造方法中要读取的文件
当你创建一个流对象时,必须传入一个文件路径。该路径下,如果没有该文件,会抛出FileNotFoundException 。
构造举例,代码如下:
public class FileInputStreamConstructor throws IOException{
public static void main(String[]args){
// 使用File对象创建流对象
File file=new File("a.txt");
FileInputStream fos=new FileInputStream(file);
// 使用文件名称创建流对象
FileInputStream fos=new FileInputStream("b.txt");
}
}
(1)
读取数据的原理(硬盘-->内存)
java程序要读取数据-->找JVM-->找OS-->OS读取数据的方法-->读取文件
字节输入流的使用步骤(重点):
1.创建FileInputStream对象,构造方法中绑定要读取的数据源
2.使用FileInputStream对象中的方法read,读取文件
3.释放资源
:read方法,每次可以读取一个字节的数据,提升为int类型,读取到文件末尾,返回-1
public static void main(String[] args) throws IOException{ // 使用文件名称创建流对象 FileInputStream fis = new FileInputStream("read.txt"); // 读取数据,返回一个字节 int read = fis.read(); System.out.println((char) read); read = fis.read(); System.out.println((char) read); read = fis.read(); System.out.println((char) read); read = fis.read(); System.out.println((char) read); read = fis.read(); System.out.println((char) read); // 读取到末尾,返回-1 read = fis.read(); System.out.println( read); // 关闭资源 fis.close(); } } 输出结果: a b c d e
-1
循环改进读取方式,代码使用演示:
public class FISRead {
public static void main(String[] args) throws IOException{
// 使用文件名称创建流对象
FileInputStream fis = new FileInputStream("read.txt");
// 定义变量,保存数据
int b ;
// 循环读取
while ((b = fis.read())!=-1) {
System.out.println((char)b);
}
// 关闭资源
fis.close();
}
}
输出结果:
a
b
c
d
e
-
虽然读取了一个字节,但是会自动提升为int类型。
-
public class FISRead {
public static void main(String[] args) throws IOException{
// 使用文件名称创建流对象.
FileInputStream fis = new FileInputStream("read.txt"); // 文件中为abcde
// 定义变量,作为有效个数
int len ;
// 定义字节数组,作为装字节数据的容器
byte[] b = new byte[2];
// 循环读取
while (( len= fis.read(b))!=-1) {
// 每次读取后,把数组变成字符串打印
System.out.println(new String(b));
}
// 关闭资源
fis.close();
}
}
输出结果:
ab
cd
ed
d,是由于最后一次读取时,只读取一个字节e,数组中,上次读取的数据没有被完全替换,所以要通过len
public class FISRead {
public static void main(String[] args) throws IOException{
// 使用文件名称创建流对象.
FileInputStream fis = new FileInputStream("read.txt"); // 文件中为abcde
// 定义变量,作为有效个数
int len ;
// 定义字节数组,作为装字节数据的容器
byte[] b = new byte[2];
// 循环读取
while (( len= fis.read(b))!=-1) {
// 每次读取后,把数组的有效字节部分,变成字符串打印
System.out.println(new String(b,0,len));// len 每次读取的有效字节个数
}
// 关闭资源
fis.close();
}
}
输出结果:
ab
cd
e
 文件复制练习:一读一写
文件复制练习:一读一写
明确:
数据源: c:\\1.jpg
数据的目的地: d:\\1.jpg
文件复制的步骤:
1.创建一个字节输入流对象,构造方法中绑定要读取的数据源
2.创建一个字节输出流对象,构造方法中绑定要写入的目的地
3.使用字节输入流对象中的方法read读取文件
4.使用字节输出流中的方法write,把读取到的字节写入到目的地的文件中
5.释放资源(先关写的再关读的)
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class CopyFileTest {
public static void main(String[] args) throws IOException, InterruptedException {
//1.创建一个字节输入流对象,构造方法中绑定要读取的数据源
FileInputStream fis = new FileInputStream("D:\\Download\\Windows\\Theme\\Footpaths\\DesktopBackground\\paths9.jpg");
//2.2.创建一个字节输出流对象,构造方法中绑定要写入的目的地
FileOutputStream fos = new FileOutputStream("src\\daily\\oct1001\\Out\\1.jpg");
int dataRead;
//3.使用字节输入流对象中的方法read读取文件
// while((dataRead = fis.read()) != -1){
// //4.使用字节输出流中的方法write,把读取到的字节写入到目的地的文件中
// System.out.println(dataRead);
// fos.write(dataRead);
// }
//3.使用数组读取
byte[] array = new byte[1024];
int dataQuantity;
while ((dataQuantity = fis.read(array)) != -1){
System.out.println(dataQuantity);
fos.write(array);
}
//5.释放资源
fos.close();
fis.close();
}
}
三、打印流
print方法和println方法完成的,这两个方法都来自于java.io.PrintStream
PrintStream extends OutputStreamPrintStream :打印流。为其他输出流添加了功能,使它们能够方便地打印各种数据值表示形式。
1.PrintStream特点
1.只负责数据的输出,不负责数据的读取
2.与其他输出流不同,PrintStream 永远不会抛出 IOException
3.有特有的方法:print,printlnvoid print(任意类型的值)void println(任意类型的值并换行)
2.构造方法PrintStream(File file):输出的目的地是一个文件PrintStream(OutputStream out):输出的目的地是一个字节输出流PrintStream(String fileName) :输出的目的地是一个文件路径
3.成员方法
继承自父类的成员方法:
- public void close() :关闭此输出流并释放与此流相关联的任何系统资源。
- public void flush() :刷新此输出流并强制任何缓冲的输出字节被写出。
- public void write(byte[] b):将 b.length字节从指定的字节数组写入此输出流。
- public void write(byte[] b, int off, int len) :从指定的字节数组写入 len字节,从偏移量 off开始输出到此输出流。
- public abstract void write(int b) :将指定的字节输出流。
注意:
如果使用继承自父类的write方法写数据,那么查看数据的时候会查询编码表 97->a
如果使用自己特有的方法print/println方法写数据,写的数据原样输出 97->97
代码演示:
public class PrintStreamTest {
public static void main(String[] args) {
try (//1.创建打印流PrintStream对象,构造方法中绑定要输出的目的地
PrintStream ps = new PrintStream("IO/print.txt");
) {
//2.如果使用继承自父类的write方法写数据,那么查看数据的时候会查询编码表 97->a
ps.write(97);
//3.如果使用自己特有的方法print/println方法写数据,写的数据原样输出 97->97
ps.println(97);
ps.println(8.88);
ps.println('a');
ps.println("HelloWorld");
ps.println(true);
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
}
输出到文件中的内容:
a97
8.88
a
HelloWorld
true
第24课 字符流
当使用字节流读取文本文件时,可能会有一个小问题。就是遇到中文字符时,可能不会显示完整的字符,那是因为一个中文字符可能占用多个字节存储。所以Java提供一些字符流类,以字符为单位读写数据,专门用于处理文本文件。
一、 字符输入流【Reader】
抽象类是表示用于读取字符流的所有类的超类,可以读取字符信息到内存中。它定义了字符输入流的基本共性功能方法。
-
public void close():关闭此流并释放与此流相关联的任何系统资源。 -
public int read(): 从输入流读取一个字符。 -
public int read(char[] cbuf): 从输入流中读取一些字符,并将它们存储到字符数组 cbuf中 。
二、 FileReader类
java.io.FileReader类是读取字符文件的便利类,把硬盘文件中的数据以字符的方式读取到内存中。构造时使用系统默认的字符编码和默认字节缓冲区。
小贴士:
中是UTF-8。
字节缓冲区:一个字节数组,用来临时存储字节数据。
构造方法
-
FileReader(File file): 创建一个新的 FileReader ,给定要读取的File对象。 -
FileReader(String fileName): 创建一个新的 FileReader ,给定要读取的文件的名称。
当你创建一个流对象时,必须传入一个文件路径。类似于FileInputStream 。
FileReader构造方法的作用:
1.创建一个FileReader对象
2.会把FileReader对象指向要读取的文件
字符输入流的使用步骤:
1.创建FileReader对象,构造方法中绑定要读取的数据源
2.使用FileReader对象中的方法read读取文件
3.释放资源
(1)读取字符数据
1.读取字符:read-1,循环读取,代码使用演示:
public class FRRead {
public static void main(String[] args) throws IOException {
// 使用文件名称创建流对象
FileReader fr = new FileReader("read.txt");//你好abc123###
// 定义变量,保存数据
int b;
// 循环读取
while ((b = fr.read())!=-1) {
System.out.println((char)b);
}
// 关闭资源
fr.close();
}
}
输出结果:你好abc123###
小贴士:虽然读取了一个字符,但是会自动提升为int类型。
:read(char[] cbuf),每次读取b的长度个字符到数组中,返回读取到的有效字符个数,读取到末尾时,返回-1
public class ReaderTest {
public static void main(String[] args) throws IOException {
//1.创建FileReader对象,构造方法中绑定要读取的数据源
FileReader fr = new FileReader("IO/c.txt");//你好abc123###
//2.使用FileReader对象中的方法read读取文件
//第二种:用read(char[] cbuf)从输入流中读取多个字符,并将它们存储到字符数组 cbuf中
char[] chars = new char[1024];//存储读取到的多个字符
int len_1 = 0;//记录每次读取的有效字符个数
while ((len_1 = fr.read(chars)) != -1){
/*
String类的构造方法
String(char[] value) 把字符数组转换为字符串
String(char[] value, int offset, int count) 把字符数组的一部分转换为字符串 offset数组的开始索引 count转换的个数
*/
System.out.println(new String(chars,0,len_1));//你好abc123###
}
//3.释放资源
fr.close();
}
}
输出结果:你好abc123###
此处用到了String类的构造方法,传入一个字符数组,转换为字符串。
String(char[] value) 把字符数组转换为字符串。
String(char[] value, int offset, int count) 把字符数组的一部分转换为字符串。
offset:数组的开始索引
count:转换的个数
三、 字符输出流【Writer】
java.io.Writer抽象类是表示用于写出字符流的所有类的超类,将指定的字符信息写出到目的地。它定义了字节输出流的基本共性功能方法。
-
void write(int c)写入单个字符。 -
void write(char[] cbuf)写入字符数组。 -
abstract void write(char[] cbuf, int off, int len)写入字符数组的某一部分,off数组的开始索引,len写的字符个数。 -
void write(String str)写入字符串。 -
void write(String str, int off, int len)写入字符串的某一部分,off字符串的开始索引,len写的字符个数。 -
void flush()刷新该流的缓冲。 -
void close()关闭此流,但要先刷新它。
四、 FileWriter类
java.io.FileWriter类是写出字符到文件的便利类,把内存中字符数据写入到文件中。构造时使用系统默认的字符编码和默认字节缓冲区。
构造方法
-
FileWriter(File file): 创建一个新的 FileWriter,给定要读取的File对象。 -
FileWriter(String fileName)
当你创建一个流对象时,必须传入一个文件路径,类似于FileOutputStream。
构造方法的作用:
1.会创建一个FileWriter对象
2.会根据构造方法中传递的文件/文件的路径,创建文件
3.会把FileWriter对象指向创建好的文件
字符输出流的使用步骤(重点):
1.创建FileWriter对象,构造方法中绑定要写入数据的目的地
2.使用FileWriter中的方法write,把数据写入到内存缓冲区中(这里有一个字符转换为字节的过程)
3.使用FileWriter中的方法flush,把内存缓冲区中的数据,刷新到文件中
4.释放资源(会先把内存缓冲区中的数据刷新到文件中)
(1)基本写出数据
写出字符:write(int b)
public class FWWrite {
public static void main(String[] args) throws IOException {
// 使用文件名称创建流对象
FileWriter fw = new FileWriter("fw.txt");
// 写出数据
fw.write(97); // 写出第1个字符
fw.write('b'); // 写出第2个字符
fw.write('C'); // 写出第3个字符
fw.write(30000); // 写出第4个字符,中文编码表中30000对应一个汉字。
/*
【注意】关闭资源时,与FileOutputStream不同。
如果不关闭,数据只是保存到缓冲区,并未保存到文件。
*/
// fw.close();
}
}
输出结果:abC田
小贴士:
虽然参数为int类型四个字节,但是只会保留一个字符的信息写出。
未调用close方法,数据只是保存到了缓冲区,并未写出到文件中。
(2)关闭和刷新的区别
因为内置缓冲区的原因,如果不关闭输出流,无法写出字符到文件中。但是关闭的流对象,是无法继续写出数据的。如果我们既想写出数据,又想继续使用流,就需要flush 方法了。
-
flush:刷新缓冲区,将缓冲区中的数据写入到文件中,流对象可以继续使用。 -
close:先刷新缓冲区,将缓冲区中的数据写入到文件中,然后通知系统释放资源。流对象不可以再被使用了。
public class FWWrite {
public static void main(String[] args) throws IOException {
// 使用文件名称创建流对象
FileWriter fw = new FileWriter("fw.txt");
// 写出数据,通过flush
fw.write('刷'); // 写出第1个字符
fw.flush();
fw.write('新'); // 继续写出第2个字符,写出成功,说明flush之后流可以继续使用
fw.flush();
// 写出数据,通过close
fw.write('关'); // 写出第1个字符
fw.close();
//close方法之后流已经关闭了,已经从内存中消失了,流就不能再使用了
fw.write('闭'); // 继续写出第2个字符,【报错】java.io.IOException: Stream closed
fw.close();
}
}
小贴士:即便是flush方法写出了数据,操作的最后还是要调用close方法,释放系统资源。
(3)写出其他数据
字符输出流写数据的其他方法
-void write(char[] cbuf)写入字符数组。
-abstract void write(char[] cbuf, int off, int len)写入字符数组的某一部分,off数组的开始索引,len写的字符个数。
-void write(String str)写入字符串。
-void write(String str, int off, int len)写入字符串的某一部分,off字符串的开始索引,len写的字符个数。
public class WriteCharArray {
public static void main(String[] args) throws IOException {
FileWriter fw = new FileWriter("IO/f.txt");
char[] chars = {'a', 'b', 'c', 'd', 'e'};
//第一种:void write(char[] cbuf)写入字符数组。
fw.write(chars);//adcde
//第二种:void write(char[] cbuf, int off, int len)写入字符数组的某一部分,off数组的开始索引,len写的字符个数
fw.write(chars,1,3);//bcd
//第三种:void write(String str)写入字符串。
fw.write("YDD&XHH");//YDD&XHH
//第四种:void write(String str, int off, int len) 写入字符串的某一部分,off字符串的开始索引,len写的字符个数。
String str = "YDDLOVEXHH";
fw.write(str,3,4);//LOVE
fw.close();
}
}
(4)追加写和写出换行
追加写:使用两个参数的构造方法FileWriter(String fileName, boolean append)FileWriter(File file, boolean append)
参数:String fileName,File file:写入数据的目的地boolean append:续写开关
true:不会创建新的文件覆盖源文件,可以续写;
false:创建新的文件覆盖源文件
换行:换行符号
windows:\r\n
linux:/n
mac:/r
public class FWWrite {
public static void main(String[] args) throws IOException {
// 使用文件名称创建流对象,加上参数true,可以续写数据
FileWriter fw = new FileWriter("fw.txt",true);
// 写出字符串
fw.write("XHH");
// 写出换行
fw.write("\r\n");
// 写出字符串
fw.write("YDD");
// 关闭资源
fw.close();
}
}
输出结果:
XHH
YDD
第25课 IO异常处理、Properties集合
一、IO异常处理
try...catch...finally
在jdk1.7之前使用try catch finally 处理流中的异常
格式:
try{
//可能会产出异常的代码
}catch(异常类变量 变量名){
//异常的处理逻辑
}finally{
//一定会执行的代码
//资源释放
}
从jdk1.7开始,try-with-resource
在try的后边可以增加一个(),在括号中可以定义流对象,
那么这个流对象的作用域就在try中有效,
try中的代码执行完毕,会自动把流对象释放,不用写finally。
格式:
try(创建流对象语句,如果多个,使用';'隔开){
//可能会产出异常的代码
}catch(异常类变量 变量名){
//异常的处理逻辑
}
代码演示如下:将f.txt的内容复制到g.txt,无需手动close。
public class IOExc {
public static void main(String[] args) {
try (
FileWriter fw = new FileWriter("IO/g.txt");
FileReader fr = new FileReader("IO/f.txt");
) {
int b;
while ((b = fr.read()) != -1) {
fw.write(b);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
二、Properties集合
1.Properties集合介绍
1.Properties集合是Hashtable集合的子类,HashTable是一个线程安全的集合,是单线程集合,速度慢,在JDK1.2之后被更先进的HashMap集合取代了。但是Properties集合却依然活跃在历史舞台,在实际开发中,经常使用Properties集合来存取应用的配置项。Properties集合是一个持久的属性集,它使用键值对存储数据,每个键及其对应值都是一个字符串。
2. HashMap集合和Hashtable集合
- HashMap集合(以及之前学的所有的集合):可以存储null值,null键。
- Hashtable集合:不能存储null值,null键。
3.Properties集合是一个唯一和IO流相结合的集合:
- 可以使用Properties集合中的方法
store,把集合中的临时数据,持久化写入到硬盘中存储 - 可以使用Properties集合中的方法
load,把硬盘中保存的文件(键值对),读取到集合中使用 - Properties集合是一个双列集合,key和value默认都是字符串
2.相关方法
(1)构造方法
-
public Properties():创建一个空的属性列表。
(2)基本的存储方法
-
Object setProperty(String key, String value):往集合中保存一对属性,调用 Hashtable 的方法 put -
String getProperty(String key):通过key找到value值,此方法相当于Map集合中的get(key)方法 -
Set<String> stringPropertyNames()
代码演示如下
public static void main(String[] args) {
//创建Properties集合对象
Properties prop = new Properties();
//使用setProperty方法往集合中添加数据
prop.setProperty("2008", "鼠年");
prop.setProperty("2009", "牛气冲天");
prop.setProperty("2010", "虎虎生威");
prop.setProperty("2011", "兔年顶呱呱");
prop.setProperty("2012", "开心闯龙年");
//使用stringPropertyNames把Properties集合中的键取出,存储到一个Set集合中
Set<String> set = prop.stringPropertyNames();
//遍历Set集合,取出Properties集合的每一个键
for (String key : set) {
//使用getProperty方法通过key获取value
String value = prop.getProperty(key);
System.out.println(key + "---" + value);
}
}
输出结果:
2012---开心闯龙年
2011---兔年顶呱呱
2009---牛气冲天
2010---虎虎生威
2008---鼠年
(3)将集合的数据写入文件的方法
Properties集合中的方法store,把集合中的临时数据,持久化写入到硬盘中存储void store(OutputStream out, String comments)void store(Writer writer, String comments)
参数:OutputStream out:字节输出流,不能写入中文Writer writer:字符输出流,可以写中文String comments:注释,用来解释说明保存的文件是做什么用的,一般使用""空字符串,不能使用中文,会产生乱码,默认是Unicode编码。
使用步骤:
1.创建Properties集合对象,添加数据
2.创建字节输出流/字符输出流对象,构造方法中绑定要输出的目的地
3.使用Properties集合中的方法store,把集合中的临时数据,持久化写入到硬盘中存储
4.释放资源
代码演示:
public static void main(String[] args) {
//1.创建Properties集合对象,使用setProperty方法往集合中添加数据
Properties prop = new Properties();
prop.setProperty("2008", "鼠年");
prop.setProperty("2009", "牛气冲天");
prop.setProperty("2010", "虎虎生威");
prop.setProperty("2011", "兔年顶呱呱");
prop.setProperty("2012", "开心闯龙年");
//2.创建字节输出流/字符输出流对象,构造方法中绑定要输出的目的地
try (
FileWriter fw = new FileWriter("IO/g.txt");
) {
//3.使用Properties集合中的方法store,把集合中的临时数据,持久化写入到文件中存储
prop.store(fw, "save data");
} catch (Exception exception) {
exception.printStackTrace();
}
}
(4)将硬盘中保存的文件(键值对),读取到Properties集合中使用的方法
void load(InputStream inStream)void load(Reader reader)
参数:InputStream inStream:字节输入流,不能读取含有中文的键值对Reader reader:字符输入流,能读取含有中文的键值对
使用步骤:
1.创建Properties集合对象
2.使用Properties集合对象中的方法load读取保存键值对的文件
3.遍历Properties集合
注意:
1.存储键值对的文件中,键与值默认的连接符号可以使用=,空格(其他符号也可以)
2.存储键值对的文件中,可以使用#进行注释,被注释的键值对不会再被读取
3.存储键值对的文件中,键与值默认都是字符串,不用再加引号
代码演示
public static void main(String[] args) {
//1.创建Properties集合对象
Properties prop = new Properties();
try (FileReader fr = new FileReader("IO/g.txt")) {
//2.使用Properties集合对象中的方法load读取保存键值对的文件
prop.load(fr);
//3.遍历Properties集合
Set<String> set = prop.stringPropertyNames();
for (String key : set) {
String value = prop.getProperty(key);
System.out.println(key + "=" + value);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
输出结果:
2012=开心闯龙年
2011=兔年顶呱呱
2010=虎虎生威
2009=牛气冲天
2008=鼠年
第26课 缓冲流
之前学习了基本的一些流,作为IO流的入门,下面我们要见识一些更强大的流,比如能够高效读写的缓冲流,能够转换编码的转换流,能够持久化存储对象的序列化流等等。这些功能更为强大的流,都是在基本的流对象基础之上创建而来的,就像穿上铠甲的武士一样,相当于是对基本流对象的一种增强。
一、概述
缓冲流,也叫高效流,是对4个基本的FileXxx 流的增强,所以也是4个流,按照数据类型分类:
-
字节缓冲流:,
BufferedOutputStream -
字符缓冲流:
BufferedReader,BufferedWriter
缓冲流的基本原理,是在创建流对象时,会创建一个内置的默认大小的缓冲区数组,通过缓冲区读写,减少系统IO次数,从而提高读写的效率。
二、字节缓冲输出流
BufferedOutputStream extends OutputStreamBufferedOutputStream:字节缓冲输出流
1.构造方法
-
BufferedOutputStream(OutputStream out)创建一个新的缓冲输出流,以将数据写入指定的底层输出流。 -
BufferedOutputStream(OutputStream out, int size)创建一个新的缓冲输出流,以将具有指定缓冲区大小的数据写入指定的底层输出流。 - 参数:
OutputStream out:字节输出流
我们可以传递FileOutputStream,缓冲流会给FileOutputStream增加一个缓冲区,提高FileOutputStream的写入效率int size:指定缓冲流内部缓冲区的大小,不指定默认大小
2.继承自父类的共性成员方法
- void close() :关闭此输出流并释放与此流相关联的任何系统资源。
- void flush() :刷新此输出流并强制任何缓冲的输出字节被写出。
- void write(byte[] b):将 b.length个字节从指定的字节数组写入此输出流。
- void write(byte[] b, int off, int len) :从指定的字节数组写入 len字节,从偏移量 off开始输出到此输出流。
- abstract void write(int b) :将指定的字节输出流。
3.使用步骤(重点)
1.创建FileOutputStream对象,构造方法中绑定要输出的目的地
2.创建BufferedOutputStream对象,构造方法中传递FileOutputStream对象对象,提高FileOutputStream对象效率
3.使用BufferedOutputStream对象中的方法write,把数据写入到内部缓冲区中
4.使用BufferedOutputStream对象中的方法flush,把内部缓冲区中的数据,刷新到文件中
5.释放资源(会先调用flush方法刷新数据,第4步可以省略)
代码演示如下:
public class BufferedOutputStreamTest {
public static void main(String[] args) {
try (
//1.创建FileOutputStream对象,构造方法中绑定要输出的目的地
FileOutputStream fos = new FileOutputStream("IOAdvanced/a.txt");
//2.创建BufferedOutputStream对象,构造方法中传递FileOutputStream对象对象,提高FileOutputStream对象效率
BufferedOutputStream bos = new BufferedOutputStream(fos);
) {
//3.使用BufferedOutputStream对象中的方法write,把数据写入到内部缓冲区中
byte[] bytes = "我把数据写入到内部缓冲区中".getBytes();
bos.write(bytes);
//4.使用BufferedOutputStream对象中的方法flush,把内部缓冲区中的数据,刷新到文件中
bos.flush();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
输出到文件中的内容:我把数据写入到内部缓冲区中
三、字节缓冲输入流
BufferedInputStream extends InputStreamBufferedInputStream:字节缓冲输入流
1.构造方法BufferedInputStream(InputStream in):创建一个 BufferedInputStream 并保存其参数,即输入流 in,以便将来使用。
BufferedInputStream(InputStream in, int size) :创建具有指定缓冲区大小的BufferedInputStream 并保存其参数,即输入流in,以便将来使用。
参数:InputStream in:字节输入流
我们可以传递FileInputStream,缓冲流会给FileInputStream增加一个缓冲区,提高FileInputStream的读取效率。int size:指定缓冲流内部缓冲区的大小,不指定默认大小。
2.继承自父类的成员方法int read()从输入流中读取数据的下一个字节。int read(byte[] b) 从输入流中读取一定数量的字节,并将其存储在缓冲区数组 b 中。void close() 关闭此输入流并释放与该流关联的所有系统资源。
3.使用步骤(重点)
1.创建FileInputStream对象,构造方法中绑定要读取的数据源
2.创建BufferedInputStream对象,构造方法中传递FileInputStream对象,提高FileInputStream对象的读取效率
3.使用BufferedInputStream对象中的方法read,读取文件
4.释放资源
代码演示:
public class BufferedInputStreamTest {
public static void main(String[] args) {
try (//1.创建FileInputStream对象,构造方法中绑定要读取的数据源
FileInputStream fis = new FileInputStream("IOAdvanced/a.txt");
//2.创建BufferedInputStream对象,构造方法中传递FileInputStream对象,提高FileInputStream对象的读取效率
BufferedInputStream bis = new BufferedInputStream(fis);
) {
//3.使用BufferedInputStream对象中的方法read,读取文件
byte[] bytes = new byte[1024];
int b = 0;//记录每次读取的有效字节个数
while ((b = bis.read(bytes)) != -1){
System.out.println(new String(bytes,0,b));
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
四、字符缓冲输出流
BufferedWriter extends WriterBufferedWriter:字符缓冲输出流
1.构造方法
BufferedWriter(Writer out) 创建一个使用默认大小输出缓冲区的缓冲字符输出流。BufferedWriter(Writer out, int sz) 创建一个使用给定大小输出缓冲区的新缓冲字符输出流。
参数:Writer out:字符输出流
我们可以传递FileWriter,缓冲流会给FileWriter增加一个缓冲区,提高FileWriter的写入效率int sz:指定缓冲区的大小,不写默认大小
2.成员方法
继承自父类的共性成员方法:
- void write(int c) 写入单个字符。
- void write(char[] cbuf)写入字符数组。
- abstract void write(char[] cbuf, int off, int len)写入字符数组的某一部分,off数组的开始索引,len写的字符个数。
- void write(String str)写入字符串。
- void write(String str, int off, int len) 写入字符串的某一部分,off字符串的开始索引,len写的字符个数。
- void flush()刷新该流的缓冲。
- void close() 关闭此流,但要先刷新它。
特有的成员方法:void newLine() 写入一个行分隔符。会根据不同的操作系统,获取不同的行分隔符。
3.使用步骤(重点)
1.创建字符缓冲输出流对象,构造方法中传递字符输出流
2.调用字符缓冲输出流中的方法write,把数据写入到内存缓冲区中
3.调用字符缓冲输出流中的方法flush,把内存缓冲区中的数据,刷新到文件中
4.释放资源
代码演示如下:
public class BufferedWriterTest {
public static void main(String[] args) {
try (//1.创建字符缓冲输出流对象,构造方法中传递字符输出流对象
BufferedWriter bfw = new BufferedWriter(new FileWriter("IOAdvanced/c.txt"));
) {
//2.调用字符缓冲输出流中的方法write,把数据写入到内存缓冲区中
bfw.write("我正在用字符缓冲输出流向内存缓冲区写入文字");
bfw.newLine();
//3.调用字符缓冲输出流中的方法flush,把内存缓冲区中的数据,刷新到文件中
bfw.flush();
} catch (IOException e) {
e.printStackTrace();
}
}
}
文件中输出结果:我正在用字符缓冲输出流向内存缓冲区写入文字
五、字符缓冲输入流
BufferedReader extends ReaderBufferedReader:字符缓冲输入流
1.构造方法
构造方法:BufferedReader(Reader in) 创建一个使用默认大小输入缓冲区的缓冲字符输入流。BufferedReader(Reader in, int sz) 创建一个使用指定大小输入缓冲区的缓冲字符输入流。
参数:Reader in:字符输入流
我们可以传递FileReader,缓冲流会给FileReader增加一个缓冲区,提高FileReader的读取效率
2.成员方法
继承自父类的共性成员方法:int read() 读取单个字符并返回。int read(char[] cbuf)一次读取多个字符,将字符读入数组。void close() 关闭该流并释放与之关联的所有资源。
特有的成员方法:String readLine() 读取一个文本行。读取一行数据。
行的终止符号:通过下列字符之一即可认为某行已终止:换行 ('\n')、回车 ('\r') 或回车后直接跟着换行(\r\n)。
返回值:
包含该行内容的字符串,不包含任何行终止符,如果已到达流末尾,则返回 null。
3.使用步骤
1.创建字符缓冲输入流对象,构造方法中传递字符输入流
2.使用字符缓冲输入流对象中的方法read/readLine读取文本
3.释放资源
代码演示如下:
public class BufferedReaderTest {
public static void main(String[] args) {
try {
//1.创建字符缓冲输入流对象,构造方法中传递字符输入流
BufferedReader bfr = new BufferedReader(new FileReader("IOAdvanced/c.txt"));
//2.使用字符缓冲输入流对象中的方法read/readLine读取文本
String line;
/*
读取是一个重复的过程,所以可以使用循环优化
不知道文件中有多少行数据,所以使用while循环
while的结束条件,读取到null结束
*/
while ((line = bfr.readLine()) != null) {
System.out.println(line);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
输出结果:
我正在用字符缓冲输出流向内存缓冲区写入文字
aaa
bbb
ccc
ddd
eee
六、综合练习:文本排序
请将以下文本信息按照序号恢复顺序,保存在新的文本文件中。
3.侍中、侍郎郭攸之、费祎、董允等,此皆良实,志虑忠纯,是以先帝简拔以遗陛下。愚以为宫中之事,事无大小,悉以咨之,然后施行,必得裨补阙漏,有所广益。 8.愿陛下托臣以讨贼兴复之效,不效,则治臣之罪,以告先帝之灵。若无兴德之言,则责攸之、祎、允等之慢,以彰其咎;陛下亦宜自谋,以咨诹善道,察纳雅言,深追先帝遗诏,臣不胜受恩感激。 4.将军向宠,性行淑均,晓畅军事,试用之于昔日,先帝称之曰能,是以众议举宠为督。愚以为营中之事,悉以咨之,必能使行阵和睦,优劣得所。 2.宫中府中,俱为一体,陟罚臧否,不宜异同。若有作奸犯科及为忠善者,宜付有司论其刑赏,以昭陛下平明之理,不宜偏私,使内外异法也。 1.先帝创业未半而中道崩殂,今天下三分,益州疲弊,此诚危急存亡之秋也。然侍卫之臣不懈于内,忠志之士忘身于外者,盖追先帝之殊遇,欲报之于陛下也。诚宜开张圣听,以光先帝遗德,恢弘志士之气,不宜妄自菲薄,引喻失义,以塞忠谏之路也。 9.今当远离,临表涕零,不知所言。 6.臣本布衣,躬耕于南阳,苟全性命于乱世,不求闻达于诸侯。先帝不以臣卑鄙,猥自枉屈,三顾臣于草庐之中,咨臣以当世之事,由是感激,遂许先帝以驱驰。后值倾覆,受任于败军之际,奉命于危难之间,尔来二十有一年矣。 7.先帝知臣谨慎,故临崩寄臣以大事也。受命以来,夙夜忧叹,恐付托不效,以伤先帝之明,故五月渡泸,深入不毛。今南方已定,兵甲已足,当奖率三军,北定中原,庶竭驽钝,攘除奸凶,兴复汉室,还于旧都。此臣所以报先帝而忠陛下之职分也。至于斟酌损益,进尽忠言,则攸之、祎、允之任也。 5.亲贤臣,远小人,此先汉所以兴隆也;亲小人,远贤臣,此后汉所以倾颓也。先帝在时,每与臣论此事,未尝不叹息痛恨于桓、灵也。侍中、尚书、长史、参军,此悉贞良死节之臣,愿陛下亲之信之,则汉室之隆,可计日而待也。
步骤:
1.创建一个HashMap集合对象,key:存储每行文本的序号(1,2,3,..);value:存储每行的文本
2.创建字符缓冲输入流对象,构造方法中绑定字符输入流
3.创建字符缓冲输出流对象,构造方法中绑定字符输出流
4.使用字符缓冲输入流中的方法readLine,逐行读取文本
5.对读取到的文本进行切割,获取行中的序号和文本内容
6.把切割好的序号和文本的内容存储到HashMap集合中(key序号是有序的,会自动排序1,2,3,4..)
7.遍历HashMap集合,获取每一个键值对
8.根据键获取值,使用字符缓冲输出流中的方法write,把值(文本)写入到文件中
9.释放资源
代码:
public class TextSort {
public static void main(String[] args) {
try (//2.创建字符缓冲输入流对象,构造方法中绑定字符输入流
BufferedReader bfr = new BufferedReader(new FileReader("IOAdvanced/乱序出师表.txt"));
//3.创建字符缓冲输出流对象,构造方法中绑定字符输出流
BufferedWriter bfw = new BufferedWriter(new FileWriter("IOAdvanced/出师表.txt"));
) {
//1.创建一个HashMap集合对象,key:存储每行文本的序号(1,2,3,..);value:存储每行的文本
HashMap<String, String> map = new HashMap<>();
//4.使用字符缓冲输入流中的方法readLine,逐行读取文本
String line;
while ((line = bfr.readLine()) != null) {
//5.对读取到的文本进行切割,获取行中的序号和文本内容
//String中的split方法,根据文本中的"."号进行切割
//被切割的部分分别存储到数组中,此处每行被切割成两部分,左边是序号,右边是内容
String[] array = line.split("\\.");
//6.把切割好的序号和文本的内容存储到HashMap集合中(key序号是有序的,会自动排序1,2,3,4..)
map.put(array[0], array[1]);
}
//7.遍历HashMap集合,获取每一个键值对
Set<String> set = map.keySet();
for (String key : set) {
//8.根据键获取值,使用字符缓冲输出流中的方法write,把值写入到文件中
String text = map.get(key);
bfw.write(text.trim());//String类的trim方法:消除首尾空格。
bfw.newLine();//换行
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
输出到文件中的内容:
先帝创业未半而中道崩殂,今天下三分,益州疲弊,此诚危急存亡之秋也。然侍卫之臣不懈于内,忠志之士忘身于外者,盖追先帝之殊遇,欲报之于陛下也。诚宜开张圣听,以光先帝遗德,恢弘志士之气,不宜妄自菲薄,引喻失义,以塞忠谏之路也。
宫中府中,俱为一体,陟罚臧否,不宜异同。若有作奸犯科及为忠善者,宜付有司论其刑赏,以昭陛下平明之理,不宜偏私,使内外异法也。
侍中、侍郎郭攸之、费祎、董允等,此皆良实,志虑忠纯,是以先帝简拔以遗陛下。愚以为宫中之事,事无大小,悉以咨之,然后施行,必得裨补阙漏,有所广益。
将军向宠,性行淑均,晓畅军事,试用之于昔日,先帝称之曰能,是以众议举宠为督。愚以为营中之事,悉以咨之,必能使行阵和睦,优劣得所。
亲贤臣,远小人,此先汉所以兴隆也;亲小人,远贤臣,此后汉所以倾颓也。先帝在时,每与臣论此事,未尝不叹息痛恨于桓、灵也。侍中、尚书、长史、参军,此悉贞良死节之臣,愿陛下亲之信之,则汉室之隆,可计日而待也。
臣本布衣,躬耕于南阳,苟全性命于乱世,不求闻达于诸侯。先帝不以臣卑鄙,猥自枉屈,三顾臣于草庐之中,咨臣以当世之事,由是感激,遂许先帝以驱驰。后值倾覆,受任于败军之际,奉命于危难之间,尔来二十有一年矣。
先帝知臣谨慎,故临崩寄臣以大事也。受命以来,夙夜忧叹,恐付托不效,以伤先帝之明,故五月渡泸,深入不毛。今南方已定,兵甲已足,当奖率三军,北定中原,庶竭驽钝,攘除奸凶,兴复汉室,还于旧都。此臣所以报先帝而忠陛下之职分也。至于斟酌损益,进尽忠言,则攸之、祎、允之任也。
愿陛下托臣以讨贼兴复之效,不效,则治臣之罪,以告先帝之灵。若无兴德之言,则责攸之、祎、允等之慢,以彰其咎;陛下亦宜自谋,以咨诹善道,察纳雅言,深追先帝遗诏,臣不胜受恩感激。
今当远离,临表涕零,不知所言。
第27课 转换流
1.字符编码
计算机中储存的信息都是用二进制数表示的,而我们在屏幕上看到的数字、英文、标点符号、汉字等字符是二进制数转换之后的结果。按照某种规则,将字符存储到计算机中,称为编码 。反之,将存储在计算机中的二进制数按照某种规则解析显示出来,称为解码 。比如说,按照A规则存储,同样按照A规则解析,那么就能显示正确的文本符号。反之,按照A规则存储,再按照B规则解析,就会导致乱码现象。
编码:字符(能看懂的)-->字节(看不懂的)
解码:字节(看不懂的)-->字符(能看懂的)
-
字符编码
Character Encoding: 就是一套自然语言的字符与二进制数之间的对应规则。编码表:生活中文字和计算机中二进制的对应规则
2.字符集
-
字符集
Charset:也叫编码表,是一个系统支持的所有字符的集合,包括各国家文字、标点符号、图形符号、数字等。
计算机要准确的存储和识别各种字符集符号,需要进行字符编码,一套字符集必然至少有一套字符编码。常见字符集有ASCII字符集、GBK字符集、Unicode字符集等。

可见,当指定了编码,它所对应的字符集自然就指定了,所以编码才是我们最终要关心的。
-
ASCII字符集 (美国)
-
-
基本的ASCII字符集,使用7位(bits)表示一个字符,共128字符。ASCII的扩展字符集使用8位(bits)表示一个字符,共256字符,方便支持欧洲常用字符。
-
-
ISO-8859-1字符集(欧洲)
-
拉丁码表,别名Latin-1,用于显示欧洲使用的语言,包括荷兰、丹麦、德语、意大利语、西班牙语等。
-
ISO-8859-1使用单字节编码,兼容ASCII编码。
-
-
GBxxx字符集(中国)
-
GB就是国标的意思,是为了显示中文而设计的一套字符集。
-
GB2312:简体中文码表。一个小于127的字符的意义与原来相同。但两个大于127的字符连在一起时,就表示一个汉字,这样大约可以组合了包含7000多个简体汉字,此外数学符号、罗马希腊的字母、日文的假名们都编进去了,连在ASCII里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的"全角"字符,而原来在127号以下的那些就叫"半角"字符了。
-
GBK(重点):最常用的中文码表。是在GB2312标准基础上的扩展规范,使用了双字节编码方案,共收录了21003个汉字,完全兼容GB2312标准,同时支持繁体汉字以及日韩汉字等。
-
GB18030:最新的中文码表。收录汉字70244个,采用多字节编码,每个字可以由1个、2个或4个字节组成。支持中国国内少数民族的文字,同时支持繁体汉字以及日韩汉字等。
-
-
Unicode字符集(万国码)
-
Unicode编码系统为表达任意语言的任意字符而设计,是业界的一种标准,也称为统一码、标准万国码。
-
它最多使用4个字节的数字来表达每个字母、符号,或者文字。有三种编码方案,UTF-8、UTF-16和UTF-32。最为常用的UTF-8编码。
-
UTF-8编码,可以用来表示Unicode标准中任何字符,它是电子邮件、网页及其他存储或传送文字的应用中,优先采用的编码。互联网工程工作小组(IETF)要求所有互联网协议都必须支持UTF-8编码。所以,我们开发Web应用,也要使用UTF-8编码。它使用一至四个字节为每个字符编码,编码规则:
-
128个US-ASCII字符,只需一个字节编码。
-
拉丁文等字符,需要二个字节编码。
-
大部分常用字(含中文),使用三个字节编码。
-
其他极少使用的Unicode辅助字符,使用四字节编码。
-
-
二、OutputStreamWriter
OutputStreamWriter extends WriterOutputStreamWriter: 是字符流通向字节流的桥梁:可使用指定的 charset 将要写入流中的字符编码成字节。(编码:把能看懂的变成看不懂)
1.构造方法
OutputStreamWriter(OutputStream out)创建使用默认字符编码的 OutputStreamWriter。OutputStreamWriter(OutputStream out, String charsetName) 创建使用指定字符集的 OutputStreamWriter。
参数:OutputStream out:字节输出流,可以用来写转换之后的字节到文件中String charsetName:指定的编码表名称,不区分大小写,可以是utf-8/UTF-8,gbk/GBK,...不指定默认使用UTF-8
2.成员方法
继承自父类的共性成员方法:
- void write(int c) 写入单个字符。
- void write(char[] cbuf)写入字符数组。
- abstract void write(char[] cbuf, int off, int len)写入字符数组的某一部分,off数组的开始索引,len写的字符个数。
- void write(String str)写入字符串。
- void write(String str, int off, int len) 写入字符串的某一部分,off字符串的开始索引,len写的字符个数。
- void flush()刷新该流的缓冲。
- void close() 关闭此流,但要先刷新它。
3.使用步骤
1.创建OutputStreamWriter对象,构造方法中传递字节输出流和指定的编码表名称
2.使用OutputStreamWriter对象中的方法write,把字符转换为字节存储缓冲区中(编码)
3.使用OutputStreamWriter对象中的方法flush,把内存缓冲区中的字节刷新到文件中(使用字节流写字节的过程)
4.释放资源
代码演示:
public class OutputStreamWriterTest {
public static void main(String[] args) {
write_gbk();
write_utf8();
}
private static void write_gbk() {
try (//1.创建OutputStreamWriter对象,构造方法中传递字节输出流和指定的编码表名称
OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream("IOAdvanced/gbk.txt"), "gbk");
) {
//2.使用OutputStreamWriter对象中的方法write,把字符转换为字节存储缓冲区中(编码)
osw.write("写入gbk编码的内容");
//3.使用OutputStreamWriter对象中的方法flush,把内存缓冲区中的字节刷新到文件中(使用字节流写字节的过程)
osw.flush();
} catch (IOException e) {
e.printStackTrace();
}
}
private static void write_utf8() {
try (//1.创建OutputStreamWriter对象,构造方法中传递字节输出流和指定的编码表名称
OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream("IOAdvanced/utf8.txt"));
) {
//2.使用OutputStreamWriter对象中的方法write,把字符转换为字节存储缓冲区中(编码)
osw.write("写入utf-8编码的内容");
//3.使用OutputStreamWriter对象中的方法flush,把内存缓冲区中的字节刷新到文件中(使用字节流写字节的过程)
osw.flush();
} catch (IOException e) {
e.printStackTrace();
}
}
}
三、InputStreamReader类
InputStreamReader extends ReaderInputStreamReader:是字节流通向字符流的桥梁:它使用指定的 charset 读取字节并将其解码为字符。(解码:把看不懂的变成能看懂的)
1.构造方法
InputStreamReader(InputStream in) 创建一个使用默认字符集的 InputStreamReader。InputStreamReader(InputStream in, String charsetName) 创建使用指定字符集的 InputStreamReader。
参数:InputStream in:字节输入流,用来读取文件中保存的字节String charsetName:指定的编码表名称,不区分大小写,可以是utf-8/UTF-8,gbk/GBK,...不指定默认使用UTF-8。
2.成员方法
继承自父类的共性成员方法:int read() 读取单个字符并返回。int read(char[] cbuf)一次读取多个字符,将字符读入数组。void close() 关闭该流并释放与之关联的所有资源。
3.使用步骤
1.创建InputStreamReader对象,构造方法中传递字节输入流和指定的编码表名称
2.使用InputStreamReader对象中的方法read读取文件
3.释放资源
4.注意事项
构造方法中指定的编码表名称要和文件的编码相同,否则会发生乱码
代码演示:
public class InputStreamReaderTest {
public static void main(String[] args) {
read_gbk();
read_utf8();
}
private static void read_gbk() {
try (//1.创建InputStreamReader对象,构造方法中传递字节输入流和指定的编码表名称
InputStreamReader isr = new InputStreamReader(new FileInputStream("IOAdvanced/gbk.txt"), "gbk");
) {
//2.使用InputStreamReader对象中的方法read读取文件
char[] chars = new char[1024];
int b;
while ((b = isr.read(chars)) != -1) {
System.out.println(new String(chars, 0, b));
}
} catch (IOException e) {
e.printStackTrace();
}
}
private static void read_utf8() {
try (//1.创建InputStreamReader对象,构造方法中传递字节输入流和指定的编码表名称
InputStreamReader isr = new InputStreamReader(new FileInputStream("IOAdvanced/utf8.txt"));
) {
//2.使用InputStreamReader对象中的方法read读取文件
char[] chars = new char[1024];
int b;
while ((b = isr.read(chars)) != -1) {
System.out.println(new String(chars, 0, b));
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
输出结果:
写入gbk编码的内容
写入utf-8编码的内容
四、小练习:
1.案例分析
-
指定GBK编码的转换流,读取文本文件。
-
使用UTF-8编码的转换流,写出文本文件。
2.代码实现
public class EncodingConversion {
public static void main(String[] args) {
try (//1.创建InputStreamReader对象,构造方法中传递字节输入流和指定的编码表名称GBK
InputStreamReader isr = new InputStreamReader(new FileInputStream("IOAdvanced/gbk.txt"), "gbk");
//2.创建OutputStreamWriter对象,构造方法中传递字节输出流和指定的编码表名称UTF-8
OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream("IOAdvanced/gbk-utf8.txt"), "utf-8");
) {
//3.使用InputStreamReader对象中的方法read读取文件
char[] chars = new char[1024];
int b;
while ((b = isr.read(chars)) != -1) {
//4.使用OutputStreamWriter对象中的方法write,把读取的数据写入到文件中
osw.write(chars, 0, b);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
JavaSE开发基础部分的笔记至此完结,感谢您的阅读,这篇笔记的内容十分重要,希望您能尽自己最大努力的全部掌握。继续阅读多线程、网络编程、单元测试、反射、注解请移步JavaSE笔记:进阶篇
Copyright © 2020-2021 AnonyEast, All rights reserved.




4 Comments
我就是来白嫖的(๑´∀`๑)
@宇宙无敌超级可爱温柔善良贤惠大方独一无二你缺一不可的小仙女是也
你好白嫖仙女
good
嘻嘻嘻,不愧是你?